
Overview
At Numbers Station, we aim to democratize data analytics and started releasing open source text-to-SQL models with NSQL and NSQL-Llama. We’re excited to announce the release of DuckDB-NSQL, a LLM built for local DuckDB SQL analytics tasks. With our amazing collaborators at MotherDuck, we continue our effort to open source data analytics tools by releasing a DuckDB specific text-to-SQL model that can run locally on your laptop.
Modern Data Stack Lives with the Data
While many modern data analytics tools live on the cloud and aim to scale to enterprise-sized datasets, there remains an increasing demand for local analytics and tooling that realizes fast responses, complete privacy, and cost effectiveness. A prime use case is the growing demand for DuckDB, a SQL analytics engine built to run entirely locally. DuckDB’s ease of use and versatility in data import and export options has resulted in a user growth of over 1.7M Python downloads just last month.
We are witnessing a parallel trend in AI with the demand for local models that can be run directly on a laptop with no third party APIs or cloud hosted models. Libraries like llama.cpp and mlx have accumulated more than 49K and 11K stars respectively. Even Apple recently announced goals to run LLMs locally on iPhones and laptops. Critically, this “on device” trend is following the paradigm “compute where the data lives” – they are portable, cost effective, and maintain privacy.
LLMs for DuckSQL
For the data analyst, LLMs promise to facilitate the analytics process by helping turn user natural questions into executable SQL (i.e. text-to-SQL). However, we have yet to witness a text-to-SQL model tailored towards local analytics. With the increasing popularity of DuckDB, a natural question is how to build a text-to-SQL model for DuckDB users. A DuckDB SQL model faces three challenges.
1.) DuckDB Dialect is Unique: DuckDB SQL dialect has idiosyncratic clauses and styles that differ from other SQL dialects like SQLite or PostgreSQL. For example, DuckDB supports GROUP BY ALL to avoid enumerating all columns whereas SQLite does not. Models trained over general SQL struggle to generate custom DuckDB syntax.
2.) Local Analytics Functions: In addition to unique syntax, DuckDB supports a wealth of custom functions tailored to local analytics that are nonexistent in other SQL dialects. For example, DuckDB supports reading parquet files with the read_parquet function. The popular open source Code Llama model, for example, drops 11 points in execution accuracy when asking it to generate DuckDB specific functions compared to standard SQL.
3.) Models (Typically) Live on Servers: Most models require specialized GPU hardware to host and run with reasonable inference times. The vast majority of users do not have access to GPUs locally and are forced to use cloud hosted models which removes any privacy guarantees from running locally.
Our DuckDB-NSQL Mode
Using our experience building NSQL, one of the first competitive open source text-to-SQL models, we are excited to release DuckDB-NSQL, a DuckDB syntax specific NSQL model. To address the above challenges we do the following:
1.) Compiling to DuckDB: we use the existing NSText2SQL dataset and transpile it to DuckDB syntax to teach the model how to “speak” in DuckDB dialect.
2.) Generating DuckDB Functions: to augment the standard SQL queries with DuckDB specific functions, we use open source LLMs to generate a 200K example training dataset of text-to-SQL pairs guided by DuckDB documentation.
3.) Release for Local Use: in addition to fully open sourcing our model weights on Hugging Face, we also release the model in GGUF format for llama.cpp – a popular package for local model use. Users on an M1 laptop can use DuckDB-NSQL.
DuckDB Training Data and Model Details
DuckDB is a newer SQL dialect, and there are no existing text-to-SQL datasets that run in DuckDB. Further, no existing dataset asks about DuckDB specific functions. To generate a diverse DuckDB specific training set, we start from the NSText2SQL dataset and transpile the queries and schema statements to DuckDB syntax. To augment this data with DuckDB custom functions and expressions, we scrape the DuckDB documentation page and use open source LLMs to generate example questions and SQL queries conditioned on specific documentation concepts. For example, we prompt the LLM to both generate a question for reading a parquet file and a SQL statement with the read_parquet function. Lastly, to provide a complex set of tables to build our training set over, we modify the tables from the popular Spider dataset to be in DuckDB format and with some added nested types such as lists and JSON. In total, we generate 200k text-to-SQL training data pairs using Mixtral-8x7B-Instruct-v0.1 model for data generation. The data covers 600 different DuckDB scalar, aggregate, and table functions, more than 40 different DuckDB expressions, and 20 DuckDB extensions.
To train the model, we use the base model of CodeLLama 7B and finetune over our DuckDB training dataset for 10 epochs with batch size 1, learning rate 1e-5 and linear decay and 10% warm up training schedule, and gradient accumulation step 8 on 8XA100 80G machine.
First Open Source Model to Quack Like a Duck
We evaluate DuckDB-NSQL on a custom test set of 75 questions hand written by a DuckDB expert. Half the questions ask standard SELECT style questions (i.e. “how many customers are there”), and the other half ask DuckDB specific questions (i.e. “read test.csv into a table called Temp”). To measure performance, we use execution accuracy of the predicted query results and gold query results as measured in https://github.com/tdoehmen/test-suite-sql-eval/tree/duckdb-only. We further compare performance of other LLMs with and without adding chunks of documentation from DuckDB using a simple embedding based retriever using OpenAI embeddings. For open source models, we compare against CodeLlama and Mixtral-8x7B-Instruct-v0.1.
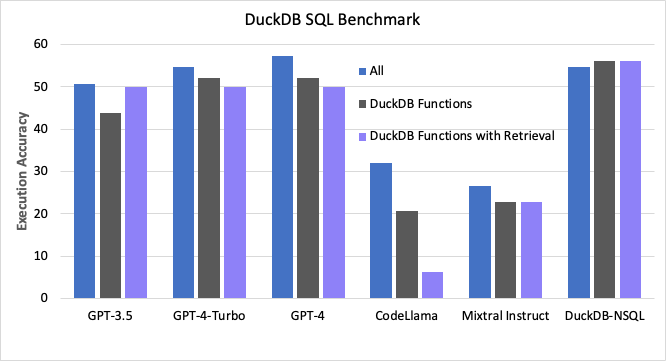
Figure 1: Execution accuracy comparison of DuckDB-NSQL compared to top performing closed and open source models. In addition to measuring performance over all questions and over the subset of DuckDB specific questions, we measure accuracy of DuckDB questions with documentation retrieval. As DuckDB-NSQL was not trained with retrieval, we do not add any documentation for that model.
As shown in Figure 1, when compared to existing open source models, DuckDB-SQL outperforms them by 20 points or more over all the test questions. When focusing on the DuckDB specific subset of the test set, we see none of the existing models are able to get above 23 points while DuckDB-SQL is at 56 points. When comparing to closed source models from OpenAI, DuckDB-SQL is within 3 points of the best performing GPT-4 over all questions and surpass them by 4 points on the DuckDB subset of queries, even after adding retrieval over DuckDB documentation. We see an interesting trend that DuckDB retrieval is helping GPT-3.5 more than the other models. We hypothesize this is because GPT-3.5 was trained on less DuckDB data from the web while GPT-4 has clearly seen DuckDB syntax. Further, the drop in performance with retrieval is likely due to the added noise to the context and can confuse models.
Qualitative Analysis
To showcase how DuckDB-NSQL performs and its failure modes compared to existing open and closed source models, we show 5 questions and the predicted SQL queries from CodeLLama, GPT-4-Turbo, and DuckDB-NSQL. The first three questions ask for specific DuckDB syntax, data type notation, and functions. For example, the first question asks for using the ORDER BY ALL notation rather than enumerating all columns while the third question uses the SUMMARIZE function. DuckDB-NSQL is accurately able to handle these queries.
The last two questions showcase how DuckDB-NSQL can be sensitive to more vague wording and benefits from more detailed questions. Question 4 asks to ‘create tmp table from test.csv’. The model incorrectly mistakes the ‘tmp’ as the table name and fails to create a temporary table. If we ask, as shown in question 5, to ‘create temporary table named tmp by selecting all rows from test.csv’, the model will correctly create a temporary table.
| Question | CodeLlama | GPT-4-Turbo | DuckDB-NSQL |
|---|---|---|---|
| get passenger count, trip distance and fare amount from taxi table and order by all of them | SELECT passenger_count, trip_distance, fare_amount\nFROM taxi\nORDER BY passenger_count, trip_distance, fare_amount | SELECT passenger_count, trip_distance, fare_amount FROM taxi ORDER BY passenger_count, trip_distance, fare_amount | SELECT passenger_count, trip_distance, fare_amount FROM taxi\nORDER BY ALL |
| get violation_type field from other_violations json column in taxi table | SELECT other_violations->>’violation_type’ FROM taxi | SELECT other_violations:violation_type FROM taxi | SELECT taxi.other_violations->’violation_type’ AS violation_type FROM taxi |
| show summary statistics of rideshare table | SELECT COUNT(*) AS total_rides, AVG(trip_miles) AS avg_trip_miles, AVG(trip_time) AS avg_trip_time, AVG(base_passenger_fare) AS avg_base_passenger_fare, AVG(tolls) AS avg_tolls, AVG(bcf) AS avg_bcf, AVG(sales_tax) AS avg_sales_tax, AVG(congestion_surcharge) AS avg_congestion_surcharge, AVG(airport_fee) AS avg_airport_fee, AVG(tips) AS avg_tips, AVG(driver_pay) AS avg_driver_pay, AVG(shared_request_flag) AS avg_shared_request_flag, AVG(shared_match_flag) AS avg_shared_match_flag, AVG(access_a_ride_flag) AS avg_access_a_ride_flag, AVG(wav_request_flag) AS avg_wav_request_flag, AVG(wav_match_flag) AS avg_wav_match_flag FROM rideshare | SELECT COUNT(*) AS total_rides, AVG(trip_miles) AS average_trip_miles, AVG(trip_time) AS average_trip_time, AVG(base_passenger_fare) AS average_base_passenger_fare, AVG(tolls) AS average_tolls, AVG(bcf) AS average_bcf, AVG(sales_tax) AS average_sales_tax, AVG(congestion_surcharge) AS average_congestion_surcharge, AVG(airport_fee) AS average_airport_fee, AVG(tips) AS average_tips, AVG(driver_pay) AS average_driver_pay FROM rideshare | SUMMARIZE rideshare |
| create tmp table from test.csv | CREATE TEMP TABLE test_tmp AS SELECT * FROM test.csv | CREATE TEMPORARY TABLE tmp AS SELECT * FROM read_csv_auto(‘test.csv’) | CREATE TABLE tmp AS FROM read_csv_auto(‘test.csv’) |
| create temporary table named tmp by selecting all rows from test.csv | CREATE TEMPORARY TABLE tmp AS SELECT * FROM test.csv | CREATE TEMPORARY TABLE tmp AS SELECT * FROM read_csv_auto(‘test.csv’) | CREATE TEMP TABLE tmp AS SELECT * FROM ‘test.csv’ |
Summary
The release of DuckDB-NSQL is a first step towards supporting local analytics by bridging the gap between local analytics via DuckDB and local LLMs. Local compute promises to bring complete data privacy and cost efficiency in an era of third party privacy concerns. This is only the beginning, and if you are interested in learning more or reaching out, please take a look at the DuckDB-NSQL blog at MotherDuck, our GitHub repo, or email us at info@numbersstation.ai.