
We are thrilled to announce the release of NSQL, a new family of open-source large foundation models (FMs) designed specifically for SQL generation tasks. We hope this effort serves as a starting point from which open-source foundation models for data/SQL can continuously improve. To do this we are releasing three models resulting from our latest research and development: NSQL 350M, NSQL 2B, and NSQL 6B. NSQL 6B outperforms all existing open-source models on standard SQL benchmarks, showing our advanced progress in open-source FM development. We hope that our work inspires others to expand upon our findings and contribute to the continuous improvement of an open-source foundation that can serve as a solid basis for further enterprise-specific customization.
The Need to Customize Foundation Models
The emergence of FMs capable of generating code from natural language instructions presents an opportunity to automate many of the tedious tasks data practitioners face today. However, off-the-shelf models are trained on public data and do not capture specific organizational knowledge (e.g., what is an active customer) that is critical to enterprise data analytics tasks and insight generation. Customizing FMs using organization-specific data provides an opportunity to capture organization-specific knowledge within the model weights and in turn will act as a flexible, continuously evolving semantic layer component in the data stack.
Democratizing Access with Open Source
To fully democratize the process of automating data analytics workflows, we are proud to introduce NSQL— a family of open-source code foundation models tailored to SQL tasks. NSQL stands out from proprietary models as it is openly accessible for commercial use. This makes NSQL an ideal starting point for organizations wanting to create their own custom model or create a semantic layer tailored to their specific needs, but are otherwise hesitant or unable to adopt closed-source alternatives in their workflow.
Challenges of using FMs in the Enterprise
As enterprises often lack the expertise to build their own code FM, they turn to available open or closed-source code FMs. Unfortunately, these FMs present challenges with respect to personalization, quality, and privacy, as we explain below.
- Personalization: General-purpose code FMs are one size fits all models built for every enterprise but tailored to none. They often lack the necessary personalization and idiosyncratic business knowledge required by data practitioners.
- Quality: Many code FMs support a wide variety of programming languages and coding tasks. This diversity means many code FMs are generalists but not specialists, and may lack the SQL and data knowledge required to work in the scope of enterprise SQL queries. For example, we find that StarCoder, one of the best open-source code FMs, drops 22 points generating complex nested SQL subqueries compared to non-nested queries.
- Privacy: Enterprises are hesitant or unable to use closed-source models due to privacy concerns and the desire to host their own models within their Virtual Private Cloud (VPC) or on-premises. Given the typically large sizes of code FMs, it can be challenging for enterprises to host a model using their existing hardware resources. Enterprises seek and benefit from a range of model sizes to better accommodate their hardware configuration.
Numbers Station Approach in NSQL Model

To overcome these challenges, Numbers Station is excited to release a family of text-to-SQL models, NSQL, built specifically for SQL specific tasks, to accelerate the development of customized enterprise FMs in analytics workflows. NSQL is the first database-agnostic, pretrained text-to-SQL model that surpasses all existing open-source models by up to 6 points in code execution accuracy. We describe our approach to addressing the challenges with existing models next:
- Open-source Model for Personalization: NSQL is a fully open-source model for academic and commercial use which democratizes access to FMs for the modern data stack. As discussed in our blog, SQL Coding Assistants Customized to Enterprise Logs, this allows organizations to reuse these models for further finetuning and customization to meet their specific needs.
- SQL Data Curation for SQL Expertise: First, NSQL is trained over a large corpus of general SQL code from the web using self-supervised learning. We then train the model to follow instructions to generate SQL based on questions and data schemas using labeled text-to-SQL pairs. By focusing on a single coding language, NSQL is able to better understand nuances unique to SQL code while generating higher quality code in comparison to general purpose code models (see Table 1).
- NSQL Model Family: We are releasing models of sizes of 350M, 2B, and 6B parameters, all trained over the same text-to-SQL data. The range of model parameters enable enterprises to handle their privacy requirements while meeting their existing hardware constraints that could otherwise pose a barrier to model deployment.
NSQL Model: Data and Training Details
Below we have identified the key details of our training data curation and model training.
Data Generation
To train NSQL, we created two training datasets: a pre-training dataset composed of general SQL queries, and a fine tuning dataset composed of text-to-SQL pairs. The general SQL queries are the SQL subset from The Stack, containing 1M training samples. The labeled text-to-SQL pairs come from more than 20 different public sources across the web from standard datasets such as WikiSQL to medical datasets such as MIMIC_III (see Table 1 for the full list of datasets). All of these datasets come with existing text-to-SQL pairs.
Additionally, we apply various data cleaning and pre-processing techniques, including table schema augmentation, SQL cleaning and the generation of better instructions with noisy instructions. The resulting dataset contains around 290,000 samples of text-to-SQL pairs. Data will be made available on HuggingFace.
Model Details
NSQL builds upon Salesforce codegen models. Our two-step training approach first continually pretrains the model with SQL code snippets. We then finetune the model on the text-to-SQL instruction data where the model is conditioned on the schema and instruction and asked to generate the SQL. The result is a SQL specialized code FM that understands SQL language and nuances of how users ask questions.
NSQL Outperforms All Open-source Models
We evaluate the NSQL family of models on two standard text-to-SQL benchmarks: Spider and GeoQuery. The Spider benchmark contains questions from over 200 diverse databases ranging from actors to vehicles while GeoQuery focuses on questions over US geography. To prevent test set overlap, we remove from our instruction tuning data any question that matches a test set question from Spider or GeoQuery or any question over a database from a Spider or GeoQuery test database. For each dataset, we report execution accuracy–which measures whether the returned execution result matches the gold execution–and exact match accuracy–which measures whether the generated query matches the gold query.
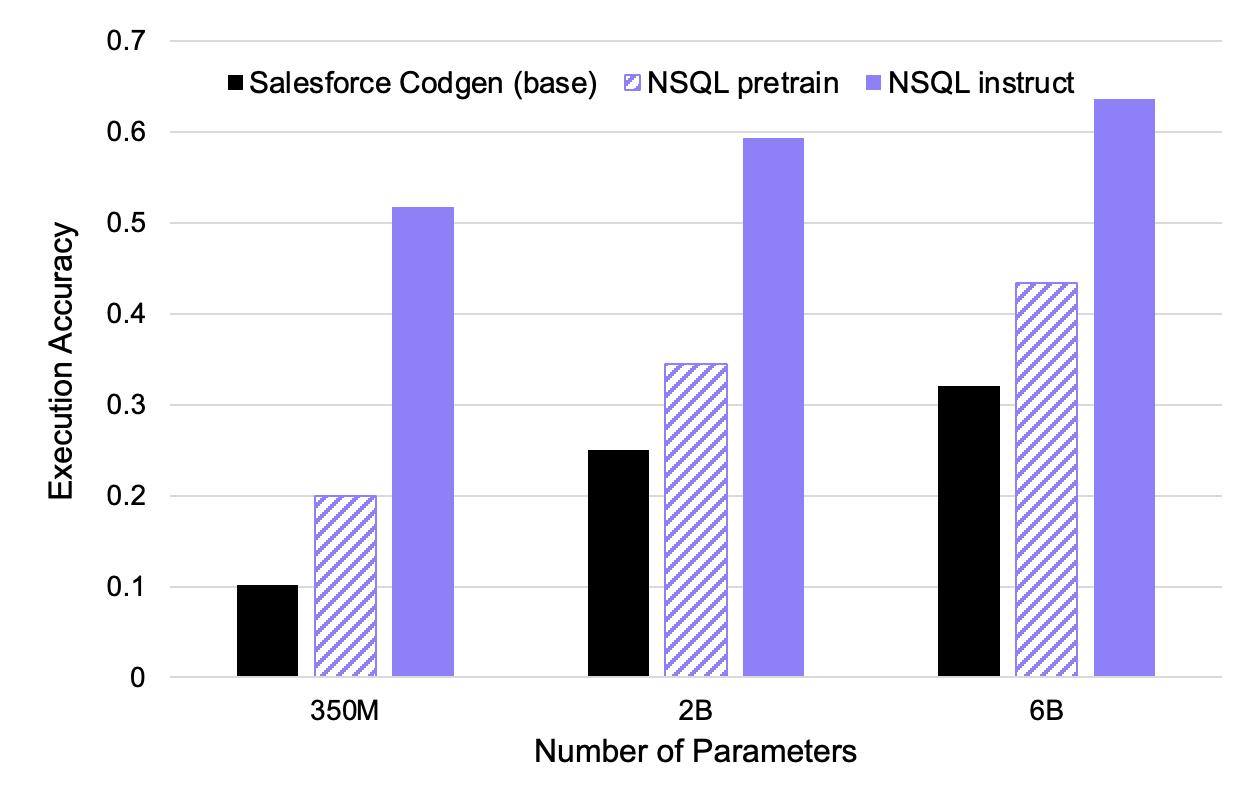
As shown in Table 2, we find that NSQL 6B outperforms all existing open-source models by up to 6 points on Spider execution accuracy, surpassing an open-source model twice its size. Even our 350M model matches the performance of a model 40 times as large. We also find that instruction tuning significantly improves execution accuracy for all model sizes, as illustrated in Figure 2.
Compared to closed-source models, NSQL 6B shows promise in further closing the gap in performance and is within 9 points on Spider execution accuracy compared to ChatGPT.
| Model | Size | Spider | GeoQuery | |||
|---|---|---|---|---|---|---|
| Execution Accuracy | Matching Accuracy | Execution Accuracy | Matching Accuracy | |||
| Open Source Other | replit/replit-code-v1-3b | 3B | 0.47 | 0.343 | 0.265 | 0.109 |
| bigcode/starcoder | 15.5B | 0.577 | 0.36 | 0.122 | 0.13 | |
| mosaicml/mpt-7b | 7B | 0.358 | 0.264 | 0.143 | 0.261 | |
| facebook/incoder-6B | 6B | 0.316 | 0.147 | 0.021 | 0.022 | |
| Salesforce/xgen-7b-8k-inst | 7B | 0.393 | 0.273 | 0.061 | 0.239 | |
| Salesforce/codegen-350M-multi | 350M | 0.102 | 0.067 | 0.02 | 0.022 | |
| Salesforce/codegen-2B-multi | 2B | 0.25 | 0.17 | 0.061 | 0.065 | |
| Salesforce/codegen-6B-multi | 6B | 0.321 | 0.226 | 0.061 | 0.109 | |
| Open Source Ours | NSQL 350M | 350M | 0.517 | 0.456 | 0.184 | 0.043 |
| NSQL 2B | 2B | 0.593 | 0.532 | 0.184 | 0.152 | |
| NSQL 6B | 6B | 0.636 | 0.574 | 0.265 | 0.152 | |
| Closed Source | Text Davinci 003 | 175B | 0.72 | 0.499 | 0.245 | 0.413 |
| GPT 3.5 Chat | – | 0.728 | 0.442 | 0.469 | 0.391 | |
| GPT 4 | – | 0.762 | 0.419 | 0.551 | 0.391 | |
Qualitative Analysis
To better understand the benefits of NSQL models as well as their failure cases, we conduct a qualitative evaluation of the models’ prediction. We present examples (Table 3) on a simple data schema (see below) to summarize some of our learnings.
Compared to general purpose code models, NSQL models can better follow instructions. For instance, we see that existing models can miss on a filter or group by clause in the instructions (see examples 1 & 2). Additionally, we observed that NSQL models hallucinate less often than existing models and only use the schema that is provided in context (see example 3). Our hypothesis is that because NSQL models are trained with a unified prompt template, they learned to better pay attention to data schemas in-context.
In terms of failure cases, NSQL models (and other open models) can struggle with complex logic that requires nested SQL (see example 4). We are excited by existing and future work that could alleviate this problem and improve NSQL models, including generating better instruction data and training on diverse sources such as SQL textbooks. Finally, we observed that NSQL models, like other open models, need explicit instructions to generate the right query. For instance, in examples 5 & 6, the models struggle to generate the right formula without the definition of revenue in-context. One exciting solution to this problem is to further finetune NSQL models on domain-specific data (e.g. documentation and data definitions) to make NSQL models better aware of organizational knowledge and business semantics.

| Example | Question | NSQL 6B | Previous Best Open Model |
|---|---|---|---|
| 1 | How many work orders are completed on time but without any listed assignee? | SELECT COUNT(*) FROM work_orders WHERE completed_date < due_date AND NOT assigned_to IS NULL; | SELECT COUNT (DISTINCT id) AS Completed_with_no_assignee FROM work_orders WHERE is_completed = true AND assigned_to IS null; |
| 2 | Latest work order by property? | SELECT property, MAX(entered_date) FROM work_orders GROUP BY property; | SELECT * FROM work_orders WHERE is_completed IS 1 ORDER BY due_date DESC, property |
| 3 | Show the property names in the US with greater than average number of work orders. | SELECT property FROM work_orders WHERE full_country_name = “United States” GROUP BY property HAVING COUNT(*) > (SELECT AVG(count) FROM work_orders WHERE full_country_name = “United States”); | SELECT property FROM work_orders LEFT JOIN company_data ON to_date(country_code_iso, ‘yyyy-mm-dd’) >= company_data.start_date WHERE country_code_iso = ‘US’ GROUP BY property HAVING COUNT(*) >= (SELECT ROUND(AVG(work_orders.id)) FROM work_orders); |
| 4 | What is the ratio of opening work orders by country? | SELECT full_country_name, COUNT(*) FROM work_orders WHERE is_open GROUP BY full_country_name; | SELECT Country, round(100.0 * cast(open_count as float) / cast(total_count as float)) [PercentOpen] FROM (SELECT full_country_name Country, count(1) open_count, count(1) total_count FROM work_orders WHERE is_open = True GROUP BY Country ORDER BY count(1) desc) as OpenOrders order by PercentOpen DESC; |
| 5 | What is the expected profit of open work orders? | SELECT AVG(cost) FROM work_orders WHERE is_open = 1; | SELECT SUM(cost) FROM work_orders WHERE is_open = 1; |
| 6 | What is the expected profit of open work orders? Profit is total difference of invoice and cost across orders. | SELECT SUM(invoice_amount – cost) FROM work_orders WHERE is_open = 1; | SELECT sum( cost ) – sum( invoice_amount ) AS expected_profit FROM work_orders; |
Conclusion: Empower Data Analysts with NSQL
At Numbers Station, our mission is to empower data and business analysts to derive actionable insights from their data. We believe that NSQL represents a great starting point to build upon and efficiently generate SQL code that will enhance productivity and reduce wasted time. We are excited to take part in the impact that open-source code generation models will have on the modern data stack.
Pioneered in the Stanford AI lab and based in Menlo Park, Numbers Station is available today in private beta by simply signing up and connecting your data warehouse. Join us on this exciting journey of transforming the world of data analytics and decision-making. You can access NSQL, along with weights, by visiting Hugging Face here or by trying out one of our example notebooks here.
If you are interested in bringing the power of NSQL and related analytics FMs to your enterprise in a personalized manner, contact us for a demo.
Let’s embrace the future of analytics together with NSQL!