
Can you spot the difference between these generated images?
Image 1
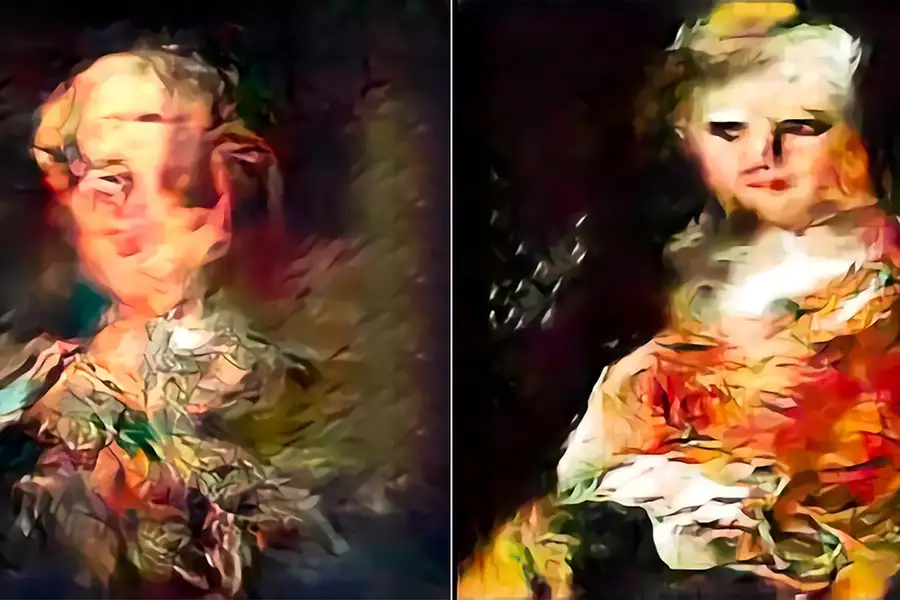
Image 2

It may be hard to recognize, but the difference lies in the datasets used to train the models which created them. The first image was generated by a model trained on images which were created by AI, while the second comes from DALL-E 3, which is trained on a mixture of real and synthetic data. The first image looks much less appealing than the second, because the former is degraded due to a feedback loop of training on images which were generated by AI — not real images from real life.
AI systems are pervasive in our day-to-day lives, and the number of daily interactions with them is ever increasing. They used to be behind the scenes — helping with recommending new content or finding search results — but with the advent of generative AI, we’ve seen an explosion of products and services where you can interact directly with powerful generative models. While these models are extremely versatile and produce convincing content, they are vulnerable to reflecting biases, drawing erroneous conclusions, and even leaking training data. High-quality data is, and always will be, paramount to the ability and behavior of AI.
Symptoms of Noisy, Biased, or Sensitive Data
AI systems have been notorious for their failures and limitations: picking up on bias in datasets, leaking private data, and hallucinating non-factual responses.
Often this is a result of poorly-chosen training data, which influences the system to take on an incorrect assumption of the world. After all, if algorithms are learning to mimic the data we give them, it should come as no surprise that generative AI will produce similar results to the data which trained it. As they say, “Garbage In, Garbage Out”.
So how can we practically clean up volumes of data?
Navigating Data Cleaning and Guardrails
Depending on the domain, there are different ways to overcome bias and noise in data. Generally, the more data you have, the less susceptible the AI system is to noise, as you will have a better approximation of the center of the distribution thanks to the law of large numbers. However, large amounts of data isn’t a silver bullet: one must take great care to ensure the data is representative of the population of interest. Note that population doesn’t just mean people — it depends on the domain!
For example, for text and natural language modeling, it’s crucial to include languages beyond just English to make a system which is accessible to many people. Furthermore in cases where data is limited, checks and guardrails during data collection is critical to ensure that it’s consistent, coherent, and suitable for use in the system. Some principles to keep in mind are:
Consistency: Are my examples consistent to each other?
Coherence: Do my examples as a collection make sense and correspond to each other?
Uniqueness: Am I duplicating any data?
Distribution: Do my data represent the population well, or am I sampling a subpopulation?
Some of the most popular AI products have heavy data-cleaning or alignment efforts to ensure that malicious prompts don’t leak sensitive data or produce inappropriate content. Examples of this are Reinforcement Learning from Human Feedback (RLHF) for Large Language Models (LLMs), cleaning training data for generative models, or guardrails to prevent producing inappropriate content. In addition, data cleaning can be attributed to large increases in accuracy. For instance, on an object detection dataset, a group found that cleaning up labels for 6.5% of images improved accuracy by 13%!
Clean data is crucial to robust and accurate predictions, as well as high-quality generated content in AI-based systems.
How Numbers Station uses Data Cleaning in Practice
At Numbers Station, we enable business users to generate insights over their data. Users can ask questions directly about their data, or let us guide them to questions they might not generate organically. As they ask questions over data and drill down to subsequent areas of interest, we collect feedback from their experience, which automatically improves our platform.
In the development of our product, we encountered the power of data first-hand. We saw some inconsistent responses to a common set of questions, which had us puzzled. In response, we analyzed our user feedback on a number of business questions, and found that we were collecting inconsistent and incoherent data, which caused the symptom of inconsistent answers to similar business questions. The data was inconsistent because, for a set of similar or even the same question, we allowed users to verify responses which were completely different. As a result, our data could become contradictory. By adding a constraint to check for consistency with our existing knowledge pool, we could ensure the data we collected was free from contradiction.
Further, one of the key components to address was in the “coherence” of our data. We found that users often started with a vague question, but after exploring their data, landed on a query which was fairly different from their original question. This iterative workflow is extremely powerful for discovering insights but somewhat misleading when it comes to using it for data to refine our algorithms. To address this gap, we introduced question re-phrasing, which allows us to combine the user’s original intent with a refined question which is coherent with the final query they were interested in. This allows other users in an organization to capitalize on the data flywheel which is built into our product, and collectively build up and draw upon a knowledge pool as the slice and dice their data for new insights.
By adding constraints, quality-checks, and improvements to our data-collection pipeline such as the ones described above, we’ve seen huge improvements in robustness for similar business questions. These guardrails help to build trust in our platform and deliver insights to our customers faster and more reliably.
If you’re interested in learning about how Numbers Station can help you unlock reliable insights, contact us today!