
Text-to-SQL generation models have a lot of potential value for data analytics. These models generate SQL queries from natural language prompts and hold the promise to democratize analytics while eliminating a lot of the tedious aspects of data processing tasks.
With the rise of large language models (LLMs), new state-of-the-art results have been achieved on academic text-to-SQL benchmarks, with the most recent GPT-4 achieving state-of-the-art by 12.6 points compared to alternatives on the Spider academic benchmark 1. Surprisingly, despite the progress in academic benchmarks, LLMs can still fail in the real-world. For example, the SEDE dataset, which contains web-scraped Stack Exchange data, demonstrated poor performance for models that performed well on Spider 2. The disparity between academic and real-world performance raises the question as to why LLMs are failing and if we can better measure their real-world performance in benchmark settings.
At Numbers Station, we aim to democratize data analytics and believe high quality benchmarks are critical to evaluating the state-of-the-art and facilitating the development of models that are effective for real-world applications. If the reason behind poor performance on real-world data can be identified and exposed with a benchmark, new text-to-SQL models can fill this gap and be better applied to speed up and democratize data analytics everywhere.
We first aim to understand what aspects of real-world SQL queries are causing performance degradation of these models.
To study the disparity in performance between academic and production workloads, we analyze customer logs to determine failure modes of text-to-SQL models on real-world applications.
Using queries from customer logs, we manually label with text questions and conduct an error analysis on model predictions to determine where the issues were concentrated. Our examples have a modified schema for privacy, but the issues were found with the predictions on actual real-world data. As described below, we identify three main failure models of text-to-SQL models: long context length, unclear question formulation, and more complex queries.
Challenges of applying text-to-SQL generative models to enterprise data
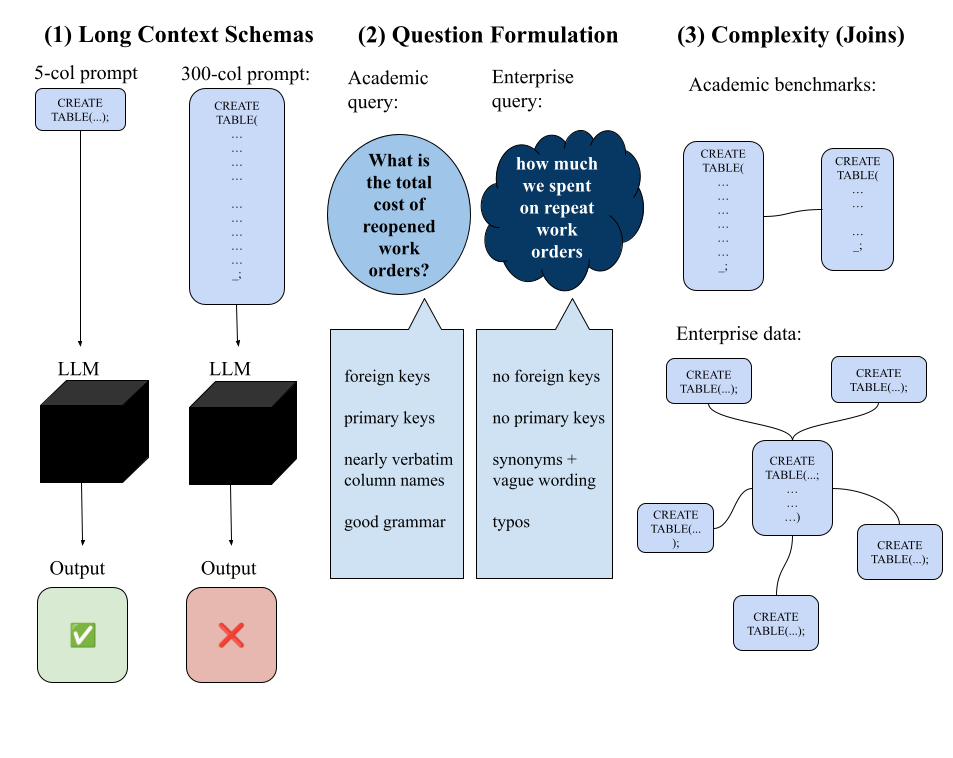
Figure 1: Three different challenges that arise when applying text-to-SQL models to real-world data: long context schemas, unclear question formulation, and join complexity.
- Context length
A good prompt is critical for generative models 3, 4, 5. Generating accurate SQL queries requires the database schema, which includes all the table and column names in the database 6. We show in Table 1, a production question over two different database schemas both containing the necessary columns for the answer, one short and one long. We see the same question with a longer schema results in a less accurate predicted query. We hypothesize that as the number of columns increases, the context length (i.e. prompt length) inevitably increases and results in performance degradation.
| Question: | Reference: | Less than 5-col schema prediction (GPT-3.5): | 300-col schema prediction (GPT-3.5): |
|---|---|---|---|
| How many of each equipment asset model is due in the next 24 hours? | SELECT wko_work_order_equipment_worked_on.equipment_asset_model, COUNT(*) FROM wko_work_order_equipment_worked_on AS wko_work_order_equipment_worked_on JOIN wko_work_orders ON wko_work_orders.id = wko_work_order_equipment_worked_on.work_order_id WHERE wko_work_orders.is_due_next_24_hours=1 GROUP BY wko_work_order_equipment_worked_on.equipment_asset_model | SELECT equipment_asset_model, COUNT(*) as count FROM wko_work_order_equipment_worked_on JOIN wko_work_orders ON wko_work_order_equipment_worked_on.work_order_id = wko_work_orders.id WHERE wko_work_orders.is_due_next_24_hours = 1 GROUP BY equipment_asset_model | SELECT equipment_asset_model, COUNT(*) FROM wko_work_order_equipment_worked_on WHERE due_at BETWEEN datetime('now') AND datetime('now', '+1 day') GROUP BY equipment_asset_model |
Long context schemas are not accurately represented in standard academic benchmarks. Standard tables in real-world use cases can have hundreds of columns. For example, one production table we examined had over 150 columns. Using a 150 column table in a text-to-SQL workload results in prompts where just feeding the schema into the prompt can consume thousands of tokens and take up to 25% of available context for models like GPT-4. If a customer is asking more complex queries over multiple tables, the available context will not be enough to fit the entire schema. In contrast, existing benchmarks like Spider, have an average of 28 columns over all tables in each database. Spider will not highlight model performance degradations as the tables are smaller due to the long context.
- Question variations
In real-world scenarios, users may pose questions that are less structured and lack details. Users often come with latent business knowledge and context that is not transferred in a question. In Table 2, we show a production question phrased colloquially compared to one we manually edited to be more precise and model-friendly. We find that the more precise question results in a more accurate SQL query. We hypothesize that the user phrasing can have a detrimental impact on model performance.
Examining customer logs, we see three main issues with how users phrase questions: 1) typos and trivial prompt sensitivity, 2) synonyms, business logic, and vague wording, and 3) lack of metadata specification (unclear table columns/joins/primary and foreign keys). Each of these issues can result in questions that are abbreviated, use synonyms for column names, or are unclear about what they are asking for. Questions also contain organization-specific knowledge and conventions that can add complexity to generation.
| In Academic Benchmarks | Question: What is the total cost of reopened work orders? | Reference:SELECT SUM(wko_service_provider_metrics.total_cost) FROM wko_service_provider_metrics JOIN wko_work_orders ON wko_work_orders.id=wko_service_provider_metrics.id WHERE wko_work_orders.reopened_at is not null | PredictionSELECT SUM(wsm.total_cost) AS total_cost_of_reopened_work_ordersFROM wko_work_orders wwoJOIN wko_service_provider_metrics wsm ON wwo.id = wsm.idWHERE wwo.reopened_at IS NOT NULL; |
|---|---|---|---|
| In Enterprise Data | Question: How much did we spend on repeat work orders ? | PredictionSELECT SUM(wsm.total_cost) AS total_spent_on_repeat_work_ordersFROM wko_work_orders wwoJOIN wko_service_provider_metrics wsm ON wwo.id = wsm.idWHERE wwo.is_repeat_order = 1; |
For example, in a customer table referencing cost, the table had a column called “price” and one called “total_cost”. Users would often use terms like “cost”, “price”, “total” to all refer to the “total_cost” table. Naming ambiguity can cause model performance drops. In addition, real-world data has more noisy and erroneous data, in addition to vague column names and a lack of primary or foreign keys and other labels. On the other hand, in Spider, the questions all reference the column names intuitively and clearly. For example, searching for “films with deleted scenes” is phrased as titles of films that include ‘Deleted Scenes’ in their special feature section” in Spider, which is less organic 6. Spider’s question “cleanliness” raises concerns about how accurately it will capture performance issues with question phrasings. Code generation models also have high sensitivity to prompt changes, so minor errors such as typos in column names or unintuitive primary keys can significantly influence the output of these models.
- Complex queries
Real-world databases have more complex schemas and users have more complex requests. In Table 3, we show a complex join over X tables and Y columns. We see a performance drop when the model is asked to join across schemas. We hypothesize that with more complex join queries, model performance will drop.
| Complex question (has joins): | Reference: | GPT-4 Prediction: |
|---|---|---|
| Which type of work order has the highest total cost? | SELECT wko_work_orders.type, SUM(wko_service_provider_metrics.total_cost) FROM wko_work_orders JOIN wko_service_provider_metrics ON wko_work_orders.id=wko_service_provider_metrics.id GROUP BY wko_work_orders.type ORDER BY SUM(wko_service_provider_metrics.total_cost) DESC LIMIT 1 | SELECT type, SUM(invoice_amount) as total_cost FROM wko_work_orders GROUP BY type ORDER BY total_cost DESC LIMIT 1 |
As shown in Figure 1, in production environments, schemas are often designed in (loosely) star-schema fashions with multiple dimension tables joining with a shared fact table. The majority of user questions require touching on one or more dimension tables with the fact tables and therefore require joins to answer correctly. Further, join conditions are rarely specified in primary key – foreign key constraints and are not always equi-join, making it challenging for a model to infer the conditions.
While 320 out of 1034 queries in the Spider dev set (about 30%) include joins, only 25% of those have complicated joins seen in production environments containing nested joins or multi-table joins. The complexity of Spider queries does not represent the complexity of real-world queries.
Our Benchmark & Results
Motivated by the above, we aim to create a better text-to-SQL benchmark that exposes the issues above. We created 50 question-query pairs using the logs we analyzed as a guide.
We created a database with 4 tables and over 300 columns. Using the database, we generated 50 SQL queries and labeled them with questions using the logs we analyzed as a guide. We included 20 non-join queries and 30 join queries. Then, we created three question variations for each query, ending in 200 total queries. We also created 4 different versions of the database with different numbers of columns, from the minimum required for all 50 queries to all 300+ columns.
Using our benchmark, we evaluate GPT-4, GPT-3.5, BigCode’s Starcoder, and NSQL Llama-2 on our benchmark as well as on the Spider benchmark.
To determine the impact of context length on performance, we evaluated five different context lengths.
Our evaluation benchmark, modeled after just 4 tables, has over 300 columns, as opposed to Spider’s average of 28.
The smallest version used only the columns required for the question in the schema, 300 tokens on average. The next smallest version used the minimum 60 columns required for any question in the schema, coming to roughly 900 tokens. There are two different versions of medium-length context, both of around 2100 tokens and 180 columns. The longest version used the full schema with all ~300 columns at 3700 tokens.

The graph demonstrates that existing text-to-SQL models are not as well-equipped to handle the massive tables that are common in real-world data. Their good performance is not maintained as the schema size increases.
To address and explore the effect of question-wording on model performance, we added question variants to the dataset. We wanted to investigate increased ambiguity as well as the opposite with more specific instructions. We also wanted to see how robust models were to trivial changes in wording. With this in mind, we created 4 different versions of each question, splitting the data into 4 variations:
- Variation 0 (Original variation): the original set of questions, e.g., “What is the total cost of reopened work orders?”
- Variation 1 (Imperative variation): Questions are rephrased in imperative form (e.g., “give me,” “show me”) with minimal alterations to word choice, e.g., “Give me the total cost of reopened work orders.”
- Variation 2 (Realistic variation): Realistic variations that use different wording for columns and more informal language, e.g., “How much did we spend on repeat work orders?”
- Variation 3 (Metadata variation): Provides explicit instructions for table joins and the associated foreign keys, “Join work_orders with service_provider_metrics on id. Return the sum of the total cost of all work orders that have been reopened.”
| Model | Total Execution | Original Variation Execution | Imperative Variation Execution | Realistic Variation Execution | Metadata Variation Execution |
|---|---|---|---|---|---|
| GPT-4 | 0.345 | 0.36 | 0.36 | 0.18 | 0.48 |
| NSQL Llama-2 | 0.16 | 0.2 | 0.18 | 0.12 | 0.14 |
| GPT-3.5 Chat | 0.365 | 0.44 | 0.38 | 0.26 | 0.38 |
| Starcoder | 0.27 | 0.28 | 0.26 | 0.18 | 0.36 |
| NSQL 6B | 0.06 | 0.06 | 0.06 | 0.04 | 0.08 |
As shown in Table 4, execution accuracy decreased from the Original Variation by an average of 12.3% on the Realistic Variation, demonstrating that there is a need for models that can address question styles that were written based on questions in real-world/enterprise settings.
Bigcode/Starcoder and GPT-4 improve on the Join Key Variation set, but not all do because they are not trained on data with such instructions. NSQL, for example, does not have FOREIGN KEY constraints during training.
Even the very minimal change from the Original Variation to the Imperative Variation led to changes in prediction quality, showing that the models are quite sensitive to variations in question phrasing. Most academic benchmarks don’t include variations, let alone 3 for each question.
To isolate performance on more complex queries, we divided data into three different buckets by type of query: queries with joins, nested queries, and everything else, i.e., simple queries. This differs from Spider evaluation, which groups queries by number of components (SELECT, GROUPBY, aggregates, etc.) as opposed to the type of components. We found that the main issues that emerge with existing models when applied to real-world use cases are with more complex queries such as joins, and some nested queries. Predictably, there is roughly 400% better performance on simple queries, while errors were concentrated in complex queries with joins.
| Model | Total Execution | Execution on Join Queries | Execution on Nested Queries | Execution on Simple Queries |
|---|---|---|---|---|
| GPT-4 | 0.345 | 0.167 | 0.125 | 0.691 |
| NSQL Llama-2 | 0.16 | 0.075 | 0.188 | 0.309 |
| GPT-3.5 Chat | 0.365 | 0.2 | 0.438 | 0.618 |
| Starcoder | 0.27 | 0.117 | 0.125 | 0.559 |
When the join issues were examined, the errors stemmed from schema interpretation and increased when more tables and/or columns were involved in the query. 76% of the incorrect predictions were caused by incorrect columns or table names. Additionally, there are occasional group-by issues where the column in the select clause is not in the group-by clause.
We find that our benchmark exposes various disparities in model performance on enterprise data. Using question variations, more complex queries (joins), and different schema lengths, we find that there is room for improvement in handling long context tasks. Existing models also need to be more robust towards ambiguity and prompt variation, and be able to be applied to more complex, convoluted data. We hope these results jumpstart research into building text-to-SQL models for enterprise settings. If you are interested in bringing the power of text-to-SQL and related analytics FMs to your enterprise, please contact info@numbersstation.ai.
1 “Introducing NSQL: Open-source SQL Copilot Foundation Models – Numbers Station,” https://www.numbersstation.ai/post/introducing-nsql-open-source-sql-copilot-foundation-models
2 M. Hazoom, V. Malik, and B. Bogin, “Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data,” arXiv (Cornell University), Jan. 2021, doi: https://doi.org/10.18653/v1/2021.nlp4prog-1.9.
3 Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. In Advances in Neural Information Processing Systems (NeurIPS).
4 P. Liu, W. Yuan, J. Fu, Z. Jiang, H. Hayashi, and G. Neubig, “Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing,” arXiv preprint arXiv:2107.13586, 2021.
5 X. L. Li and P. Liang, “Prefix-tuning: Optimizing continuous prompts for generation,” arXiv preprint arXiv:2101.00190, 2021.
6 R. Sun et al., “SQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data,” Jan. 2023, doi: https://doi.org/10.18653/v1/2023.findings-emnlp.39.