
AI agents have taken the world by storm. We are fascinated by this technology and how it’s reinventing enterprise workflows, as well as consumer applications. Lately, there has been a lot of hype around agents, and the term is often overused used to basically rebrand any AI product, whether it’s agentic or not. In this blog, we are going back to the basics of what an AI agent is, and we’ll go over a concrete example of building an agent from the ground up.
As a concrete use case, we will take natural language querying, which involves answering natural language questions by querying a structured database. Natural language querying has been an active research topic in the machine learning community for decades now. Back in 2013, researchers were training LLM precursors such as LSTMs to generate SQL code (Yin & Neubig, 2017). The popular Spider benchmark (Yu et al., 2018) has been a core enabler of such research, providing a large-scale dataset for evaluating text-to-SQL models (Guo et al., 2019). However, despite significant investments in this area, the problem was too difficult for the models, data and compute available at the time, and text-to-SQL never made it into production applications, despite AI practitioners’ enthusiasm. The release of ChatGPT in 2021 and early text-to-SQL demos created an “aha” moment in the field. Excitement surged as the technology appeared to be finally production-ready. Yet, while impressive demos were abundant, the reality of deploying natural language querying systems at scale remained complex.
Fast forward to 2025, we’re proud to say that Numbers Station’s query agent is deployed in production and used daily across Fortune 500 organizations. So what is our secret sauce, and how did we get there? In this blog, we’ll break it down step by step (note: the framework presented here is a simplified version of our query agent, tailored for illustrative purposes).
Problem Setup
To simplify the setup, let’s assume we have a single table stored in a data warehouse, and that we want to build an AI product that takes natural language questions and answers them by running SQL queries against that table.
Solution
Approach 1: LLM only — Zero- or Few-Shot Prompting
The quick and dirty way to build a natural query engine is to prompt an LLM to generate SQL queries from natural language questions. Most models are trained on internet content which involves a vast amount of SQL queries (e.g. Spider itself is in most pretraining corpuses) which makes these models familiar with the SQL syntax and logic. A popular early technique (dating back to the original GPT-3 paper in 2021) is called in-context learning. The idea is to construct a simple prompt that includes an instruction, a preview of the table schema and a question and feed it to the model so it can generate a SQL query (this would be the zero-shot approach). This can already produce reasonable results with no in-context examples, and one could further improve quality by providing a couple of hand-crafted in-context example question-SQL pairs (this would be the few-shot approach) (see Figure 1).
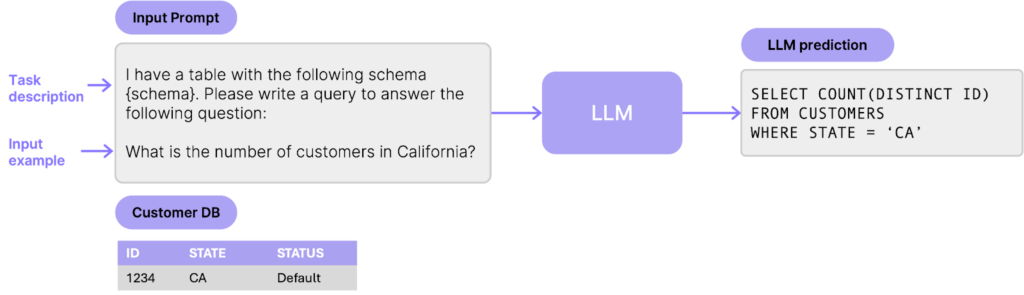
This simple approach would take a couple lines of code to implement using third-party model APIs, and is great to get a proof of concept working. However, it has a major drawback: The model outputs are not actionable. LLM taken as-is are just text generation machines so they can’t take actions based on the resulting query. In this example, a user would need to manually copy the generated query and run it on the data warehouse to get the final results. This is obviously not ideal and so we need a better solution with actionable outcomes.
Approach 2: LLM + Tools — From words to actions
Enter LLM tools. The idea is to use external tools as an additional step after the LLM generation step. Given a natural language query, the LLM will first generate a SQL query, which will be then be sent as input to the execution tool so it can execute it and return a table result. The main question in building such a system is how to transition from the LLM response into the database tool? Earlier versions of tool use relied on deterministic rules to implement the control flow of operations. For instance, one could use a deterministic SQL parser to get a query from the LLM output and send it to the tool only if the query can be parsed successfully.

This approach is much better than the first one since it incorporates actions, however, it still has a major flaw: The control flow of operations is manual and lacks agency. If, for instance, the query fails due to a schema mismatch or missing table, what should happen next? It might make sense to send back the query to the model so it corrects it, however, building such deterministic rules quickly becomes intractable as it is impossible to cover all the different edge cases that may occur at runtime.
Approach 3: LLM + Tools + Decisions — AI Agents
At a high level, we can start talking about agents when LLMs not only have access to tools, but they can make decisions about when to use these tools. Unlike the previous approach, the control flow of operations is non-deterministic and decided by the agent itself. It can decide to generate a query, call a tool, or just reply to the user. The benefit of this approach is it can cover much more complex scenarios, without the need to implement hard-coded rules for all the edge cases that can occur during runtime.
In practice, this is done via a functionality of LLM models called tool calling, where available tools are presented to the model in its context prompt, so that it can decide whether to simply generate text or generate a tool call. For instance, the model can first generate a query, then decide to call a tool to execute it, then fix it by regenerating a new query and executing it again. We can also provide more tools to the model such as tools to retrieve metadata such as metric definitions.
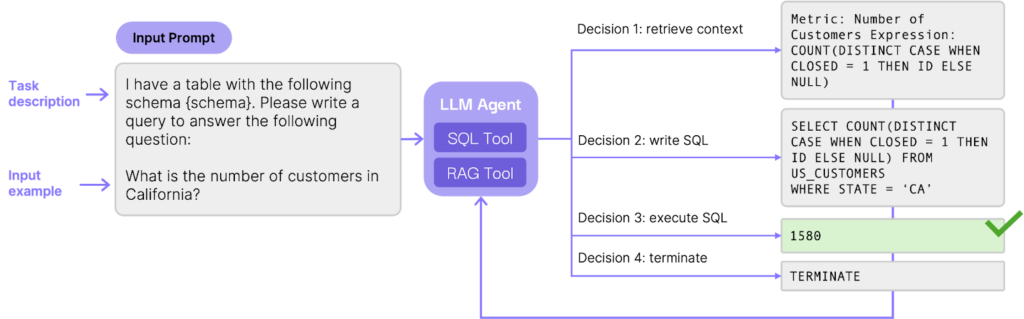
AI agents go beyond simple generation and tools, they can intelligently decide what actions to take and iterate to deliver actionable outcomes. These agents are a powerful abstraction that can be used to develop high-value applications across industries and organizations.
Conclusion
This wraps up this initial blog on how to build an AI agent. The setup we looked at in this blog is relatively straightforward: a single table and a simple natural language question as input. In reality, the setup can be much more complex: e.g. there could be multiple datasets, each with multiple tables and complex joins, a user could ask a question that is not answerable with the data available, queries might require complex business logic that cannot simply be inferred from the database schema, and more. To build a robust system that works in these scenarios, we need more agents, such as a search agent to search over the available data, or a clarification step to make sure the query is answerable. This can be implemented using a multi-agent system which will be the focus of our next blog.
If you enjoyed the read, feel free to subscribe to the mailing list to learn more about AI Agents, and how to productize them in enterprise applications.
Numbers Station’s best inbound source is organizations that failed to implement a DIY approach to bring AI into their data products. If you are still experiencing challenges productizing AI data products, feel free to contact us to learn more about our embedded AI platform.
DIY doesn’t mean do it alone.