
At Numbers Station, we believe that AI can empower organizations to make data-driven decisions faster, better, and at a broader scale than ever before. Generative AI has been revolutionary and ultimately underpins our platform, but a less-glitzy aspect that is equally critical to our success is the use of embeddings. Numbers Station utilizes embeddings and vector similarity search to enable efficient searching of large sets of data and provide highly relevant suggestions within every conversation. In this blog, we explore what embeddings are, where we store them, and how we envision the future.
.
What are embeddings?
Embeddings are dense vector representations of data that capture the semantic meaning and relationships between different pieces of information. Instead of using raw data or high-dimensional features, embeddings map data to a lower-dimensional space where similar items are closer together. This transformation allows for efficient similarity searches and more effective data analysis. In simpler terms, embeddings help us understand and organize data in a way that machines can easily interpret and act upon.
.
Full Text Search
Initially, when we implemented text search, we reached for ElasticSearch. However, our app had already relied on Postgres and we were hesitant to add complexity by adding another dependency on an external service. The Numbers Station infrastructure team ascribes to principles of radical simplicity and prefer to choose boring technology. From our early research, it seemed that ElasticSearch might be faster than Postgres for full text search over 1M+ records and provide better control over ranking than Postgres. If we solely cared about “picking the right tool for the job”, we’d probably add ElasticSearch as a backing service and take on the complexity of mapping data from Postgres to related data in ElasticSearch and keeping them in sync.
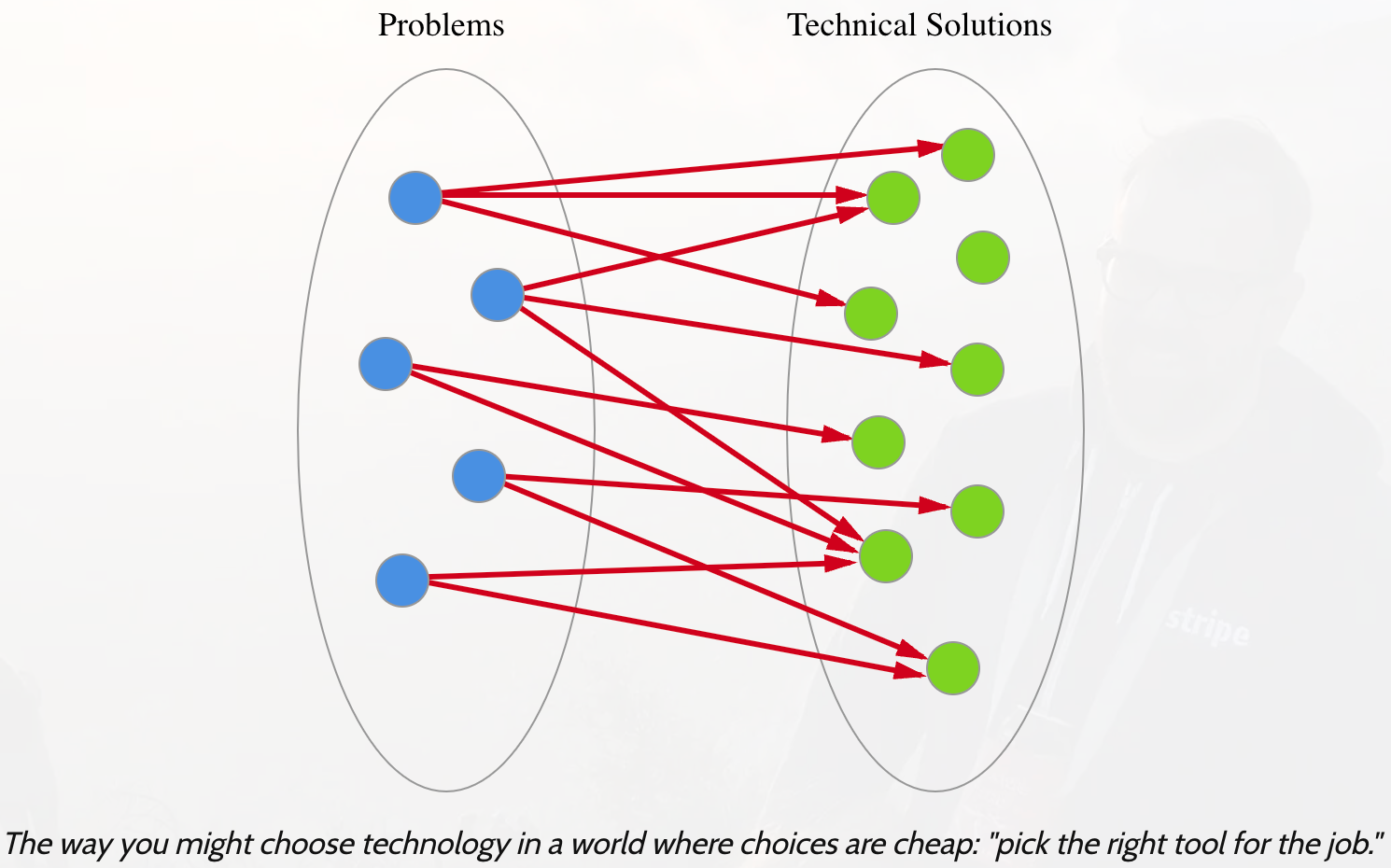
However, since we value limiting complexity, we opted to lean into Postgres for full text search. This allows us to build faster while we learn, while still leaving a future option to add in ElasticSearch. At Numbers Station, we strongly believe in the principle of two-way doors and this is a straightforward example.

Vector Search
Similar to text search, we recognize that there are many options for vector search. Initially, we thought about using ElasticSearch for vector search, or a dedicated Vector Database like Weaviate or Vespa. However, leaning into radical simplicity meant finding a way to store and manage these embeddings with existing tools. For this, we decided to use Postgres in conjunction with PGVector. PGVector is an open-source Postgres extension that is supported out of the box by AWS. Choosing to use an open source tool comes with the added benefit of lots of community-adjacent knowledge sharing. For example, the Lantern blog has several Postgres + PGVector examples and deep dives – Search, Vector Databases, Embedding tables, PG vs Pinecone.
Another benefit to using Postgres directly is the limited overhead. If we used a separate vector database, our current queries would incur a larger maintenance burden. We join with several tables, sort on multiple columns, and have several filters. We also use SQLAlchemy, rather than writing the queries manually. Given all this, our embedding search queries are faster and easier to comprehend than if we needed to perform the search in Elastic and then filter those results based on fields stored in Postgres.
Below is a table showing our Query Response Times over the last week for embedding searches.
| Query Response Time (latency) | |||
| Query Count | AVG | P50 | P90 |
| 731 | 375 ms | 240 ms | 648 ms |
Why are embeddings valuable?
At Numbers Station, we rely heavily on LLMs. Using embeddings to perform Retrieval Augmented Generation (RAG) is vital to ensure accuracy, increase speed, and lower costs. Invisible to the user, every time a question is asked, Numbers Station calculates the distance between hundreds of thousands of embeddings to find the most relevant dimensions and metrics in the knowledge graph. This ensures that even uncommon terms in the user’s query are considered.
.