
Today, the UX for Large Language Models (LLMs) is an unsolved problem. While no one really knows the most ergonomic way to allow users to interface with AI, there is one point that has become abundantly clear: writing prompts is hard. Consequently, asking end users to be prompt engineers is not scalable. It is already a burden for data experts to craft the right question. Why should we expect users who want to ask business questions against data to know the right string of tokens to ask? More plainly, asking users to engineer prompts goes against one of the pillars of great UX design: “don’t make me think.”
At Numbers Station, we approach this problem with a design system. We call it “optioneering”. Optioneering is a portmanteau of “option” and “engineering”. As you might expect, the word describes creation via a selection of choices. Whereas engineering is an applicative process (i.e. applying math and science to solve problems), optioneering is the curative process (i.e. selection from a list of provided solutions).
A little context: at Numbers Station, we are building an AI platform for business users to easily interact with their company’s complex data. Using a single natural language query, users are able to query across dozens of data sources in their data warehouse using our managed semantic layer. But we have a goldilocks problem. How do we give users just enough control to allow them to steer to the right query, but not so much control that they can drive off a cliff?
Optioneering strikes the right balance of control and guidance. Users should not be expected to be engineers to use your platform, nor should they be pandered to. Instead, treat them as optioneers.
| Engineering | Total control ❌ |
| Optioneering | Optional control ✅ |
| “Automagic” | Zero control ❌ |
In this blog post, we will outline how optioneering addresses a few major problem areas of LLM UX:
- Writer’s block – how to get users over the cognitive friction of getting started.
- Question validation – how to make users successful and validate their queries for them.
- Human in the loop – how to present what the model is thinking to the user.
.
Writer’s block
It turns out that clicking is easier than typing. Too much choice can be bad. It leads to analysis paralysis. “What am I supposed to do?” should not be the first question someone asks after opening your app.
This is a problem for many LLM apps – there are too many directions to go. If I am a data analyst for an investment firm, and I am asked to plan an investment strategy for the next 6 months, where do I even start?
Within the framework of optioneering, the interface should prioritize clickable options over other manual inputs, such as typing. In our application, the homepage shows a list of suggested questions to the user. All a user needs to do is click and think later. Down below in the periphery is the manual user input if the user wants it. This prioritization reduces cognitive load because it does not force the user to think if they don’t want to.
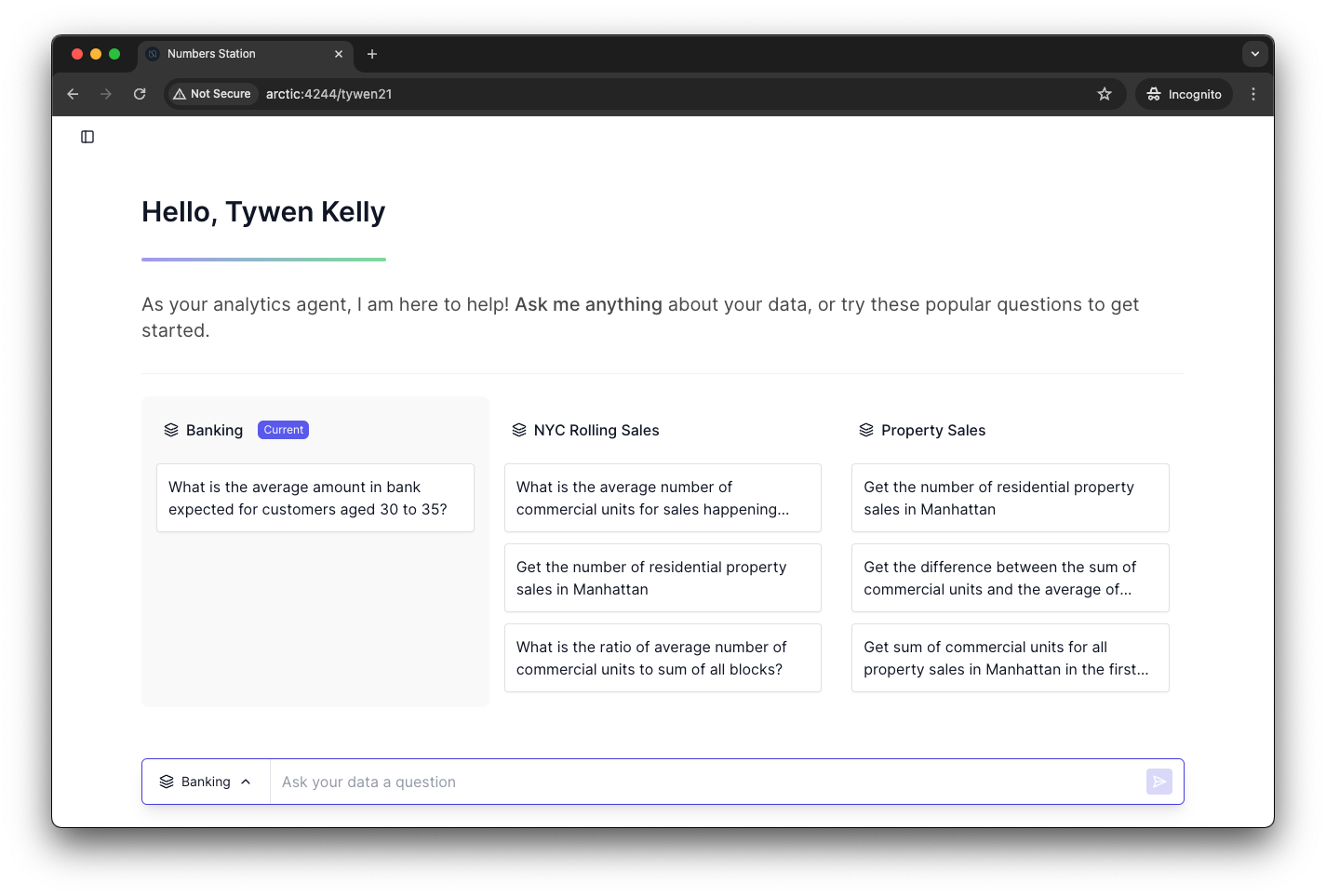
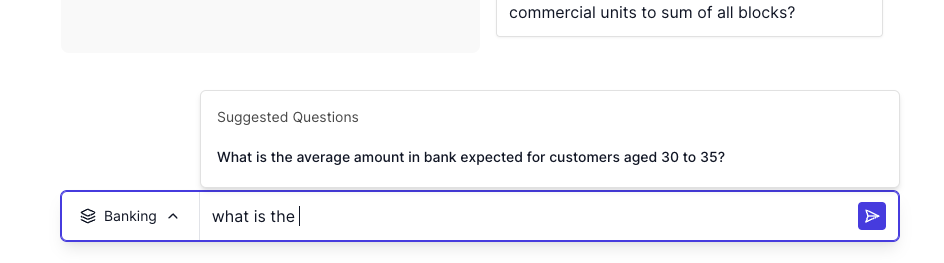
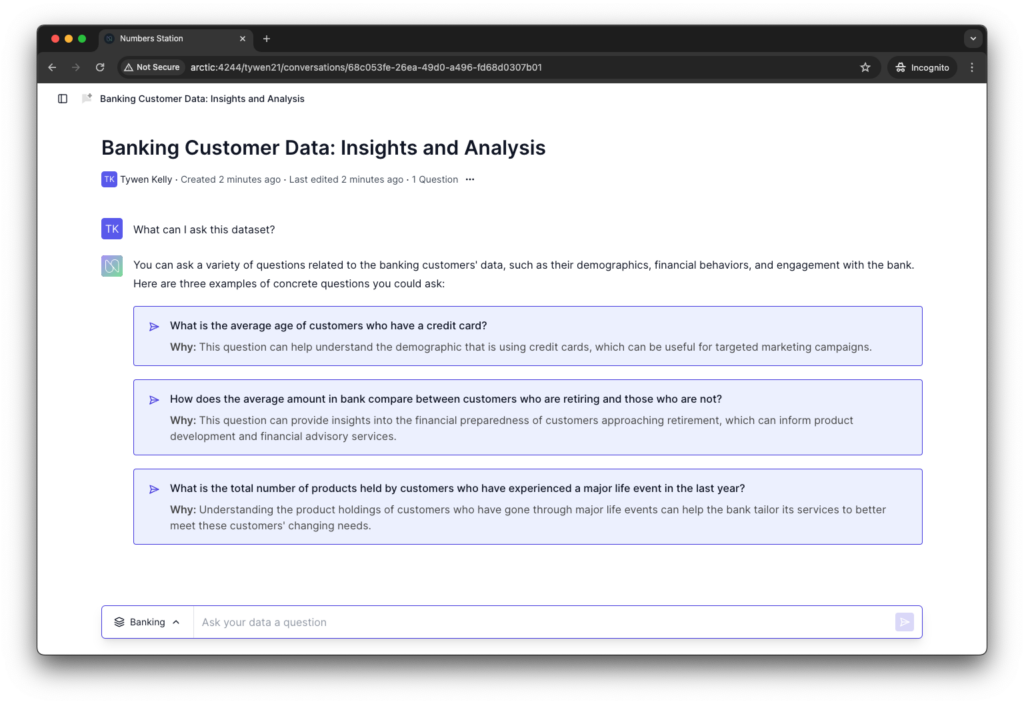
The solution to writer’s block is to replace writing with clicking. “Clicker’s block” does not exist. Do not put users in a position where they are forced to think. If they want to take the reins, they should always have that ability, but the overall design of your application should default to constructing a successful path with clickable options.
.
Question validation
In the domain of data analysis there is an infinite list of permutations for querying a dataset. If your users get past writer’s block, then they will immediately bump up against the problem of question validation: how do they know if the question can even be asked against their corpus of data?
Within the principles of optioneering, the best way to approach this is to:
- Validate questions for the user in backend
- Present rephrased and valid variants of their invalid question in the frontend
For instance, in our system we have agents that validate user questions before trying to generate and transpile them into valid queries against the semantic layer. (See: Meadow, our open source agent framework for data analysis). One such agent, called a Clarification Agent, detects invalid questions and responds with a clarification question and suggested variants.
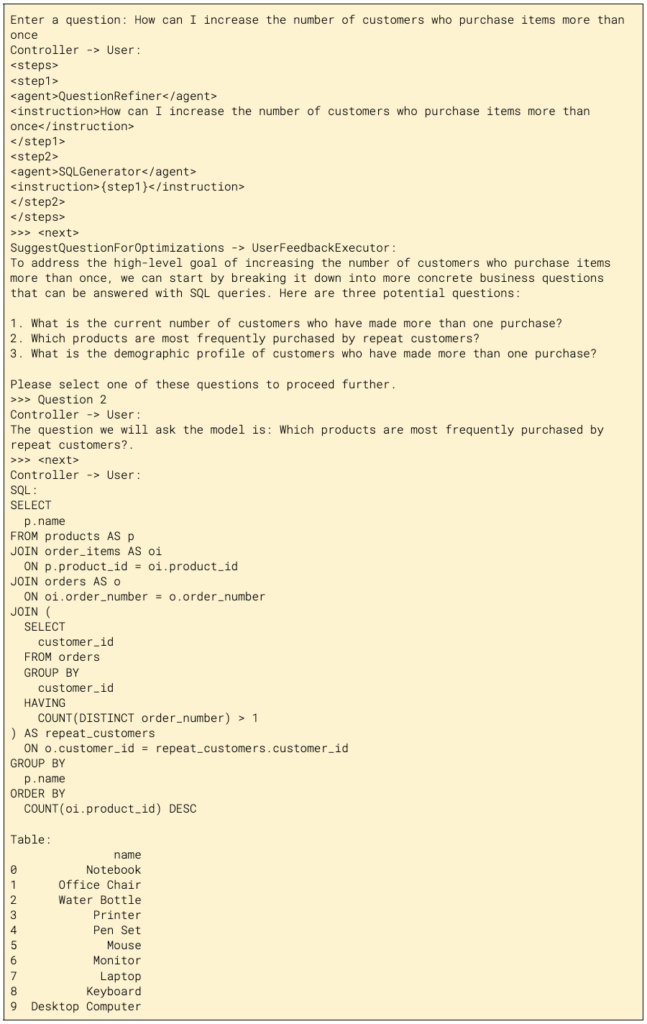

.
Human in the loop
“…it is extraordinarily hard to teach a human how to work together with a probabilistic system in an environment where they are not used to one.”
Davis Treybig
The UX of LLMs poses a novel problem: how to teach users that computers no longer always do what they are told.
Models can fundamentally be thought of as compression machines. Running a model “decompresses” the model using input tokens that squeeze out a different string of tokens. The “randomly” twisted and gnarled string of characters that emerges is a result being pushed through the model; the string is a battered result from a dense forest of statistical dimensions nudging and grabbing it on its way out. This Pachinko-like system can yield surprising results, and can be hard to grock as an end user, for a few reasons:
- Users have trouble deciphering the walls of text output by models
- Users have low trust in a system when they don’t understand how the model got to its answer
- Users need a way to course correct a model output
If the job of running the model is to decompress and reveal emergent information, the job of UX is to recompress it. In all three of these cases, optioneering is a valuable lens to understand an effective and clear way to effectively re-compress and repackage the output into a more understandable and structured format.
.
Structure the walls of text
To address the first problem, it is important to keep the users in the loop and be transparent about what the model is outputting. We encourage a two pronged model:
- Polish the structured output of the model with UI elements
- Have a deprioritized affordance to reveal the verbose message
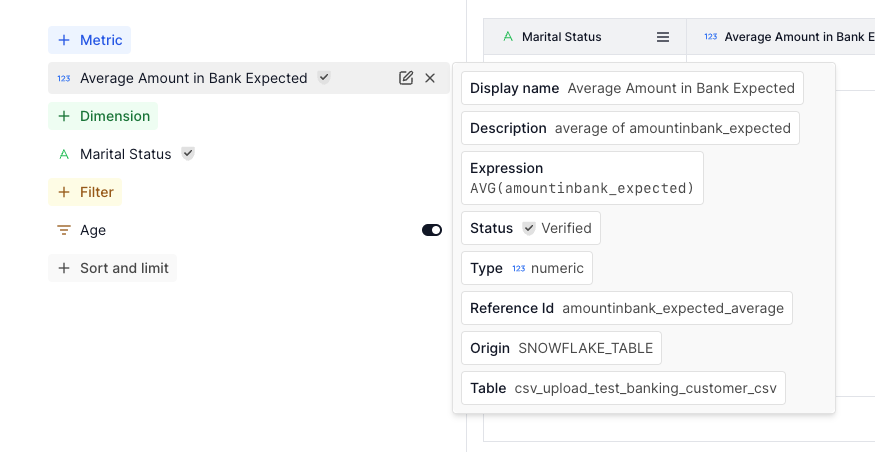
Behind the scenes, our model ultimately generates SQL to run in data warehouses. But, to the user, it is much easier to understand a structured and semantically meaningful map. Average Amount in Bank Expected is much easier to parse that AVG(amountinbank_expected). The benefits of this abstraction compounds as the metrics get more complex.
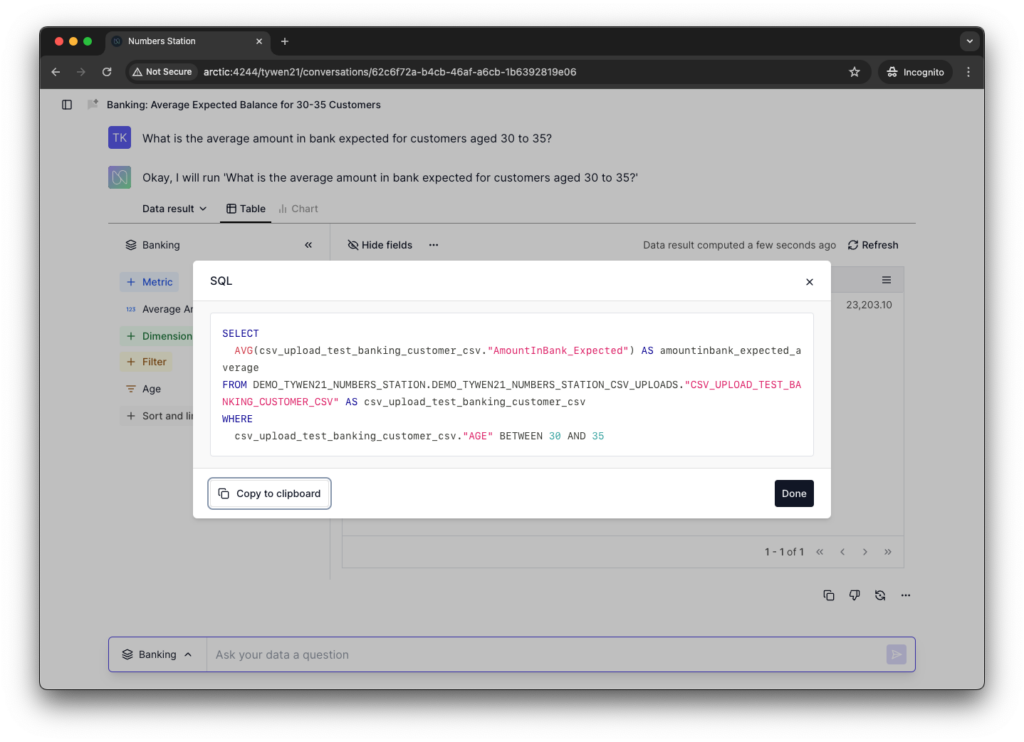
However, we also provide an affordance to peek under the hood and give the users the unparsed SQL. This is useful, for instance, if users want to manually run the query directly in their warehouse. 95% of the time users are happy with the abstracted language around dimensions and metrics – but in the edge case, it is critical to present the option to get access to the base information.
.
Build trust
Models can be asked to explain the process by which they generated a result. Lean into this – the UI should explain why the response was generated, and give the users the option to self-inspect the result. In many cases in the explanation it becomes clear that the users’ question did not include enough context, and that the model did exactly as it was told. The user can follow up and tweak their input. This iterative process builds trust between the user and the model, and is enabled by simply asking the model to “show its work”.
At Numbers Station we build this option of rendering the provenance into each semantic query generation. The provenance is a way for the model to self-reflect and also tell the user its thought process in coming up with the result. Providing this transparency is crucial to building trust with the user.
.
Course correction
When navigating the probabilistic, and sometimes unexpected, nature of LLM responses, it is important to give users levers they can use to steer the model. The best way to present these levers, is again, through the interface of options!
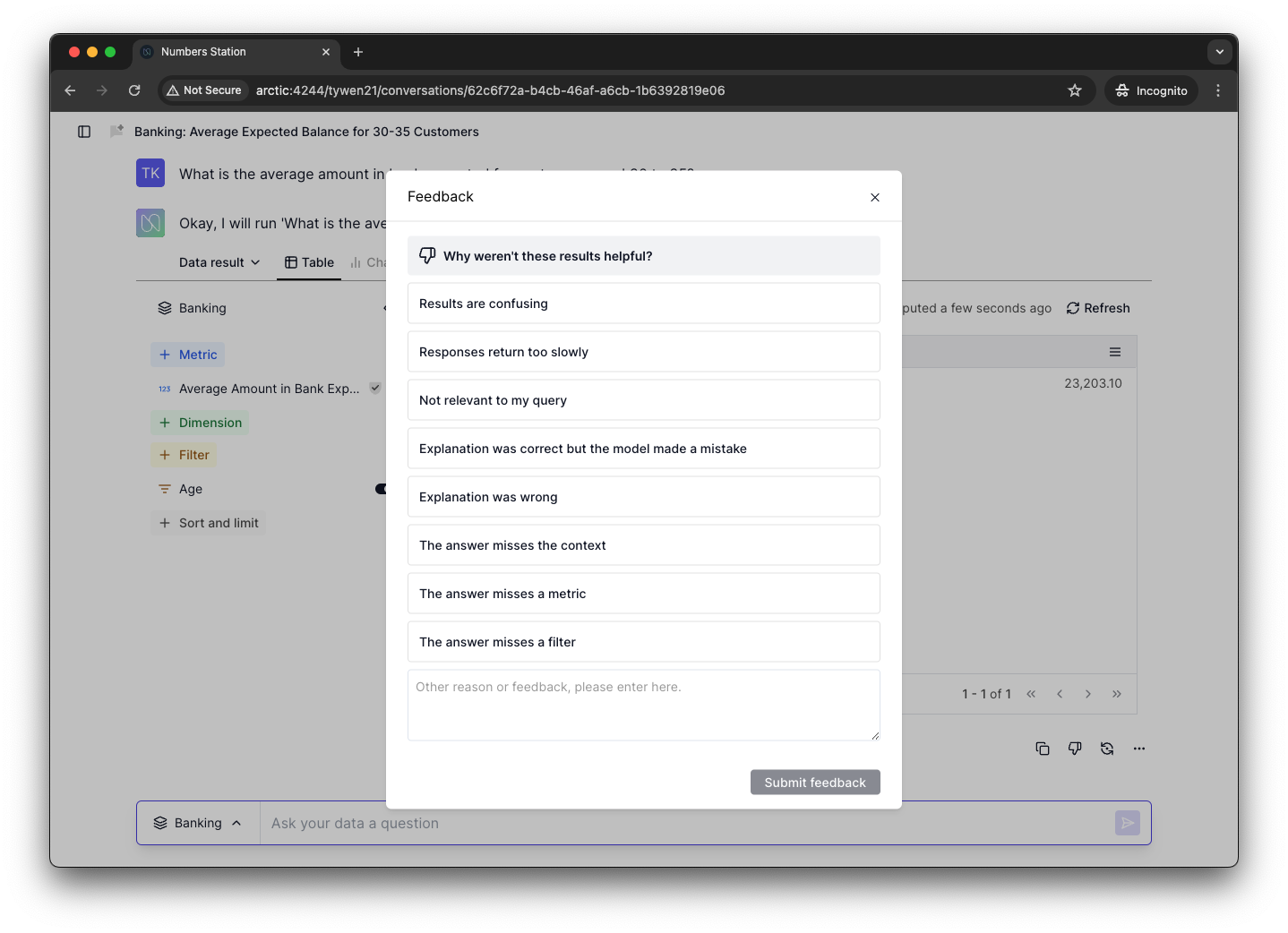
Numbers Station allows users to give feedback to correct and invalid model outputs. We utilize optioneering so that there is a prioritized list of common feedback responses, with a path at the bottom of the modal that allows users to manually enter feedback. Users are much more likely to provide feedback if they do not have to type anything.
Another area where users should be able to course correct is upstream, where the model itself builds its context. Within Numbers Station, all queries are constructed via the semantic layer: a list of reusable SQL modules that can be built together like LEGO blocks to construct a query consistent with business definitions. This semantic query is used as a reference point for the model, and parts of the semantic layer are retrieved during prompt input.
The design of the semantic layer is a result of optioneering. It is easier to modularize semantic definitions of a business (i.e. Number of users or Profit) than it is to construct raw SQL statements. The semantic layer is effectively a list of options; a list of reusable building blocks. The UX for maintaining and updating the semantic layer follows suit. Modifying it resembles turning a switch on and off: when a data expert notices a metric is no longer supported or active, they can easily toggle it to “deprecated”.
This type of course correction—allowing users to steer model output while modifying the model input—is crucial to generating good quality results. The interface to enable this is best understood as a system of switches—users should be clicking, not writing their own system prompts!

.
Conclusion
LLMs are a bit like a wild animal. Powerful, but if unconstrained, they can be hard to “read” and difficult to approach. Optioneering is a framework that allows users 1) to approach LLMs with clickable options, 2) be confident they are asking valid questions against the model, and 3) is a design principle for structuring LLM’s text output to allow users to understand (and steer) the otherwise wild process of model text generation.
The domain of LLM UX is actively developing and emerging. It is both a science and an art. The stakes, however, could not be higher: the AI application with the more optioneer-ed UX will have higher utility through its differentiation from the thousands of other applications incoherently built on LLMs. At Numbers Station, we firmly believe that optioneering is a critical UX principle to making users successful.
.