
The rise of foundation models (FMs) has heralded a new era in enterprise applications, especially in the realm of data analytics. These AI models promise to accelerate businesses and drive innovation. However, organizations going down this path should carefully consider a fundamental question: should they own a private FM or rely on a third-party FM, such as OpenAI, accessed via APIs? While the answer may not be straightforward, it’s crucial to evaluate the pros and cons of both options.
The Allure of Third-Party FMs
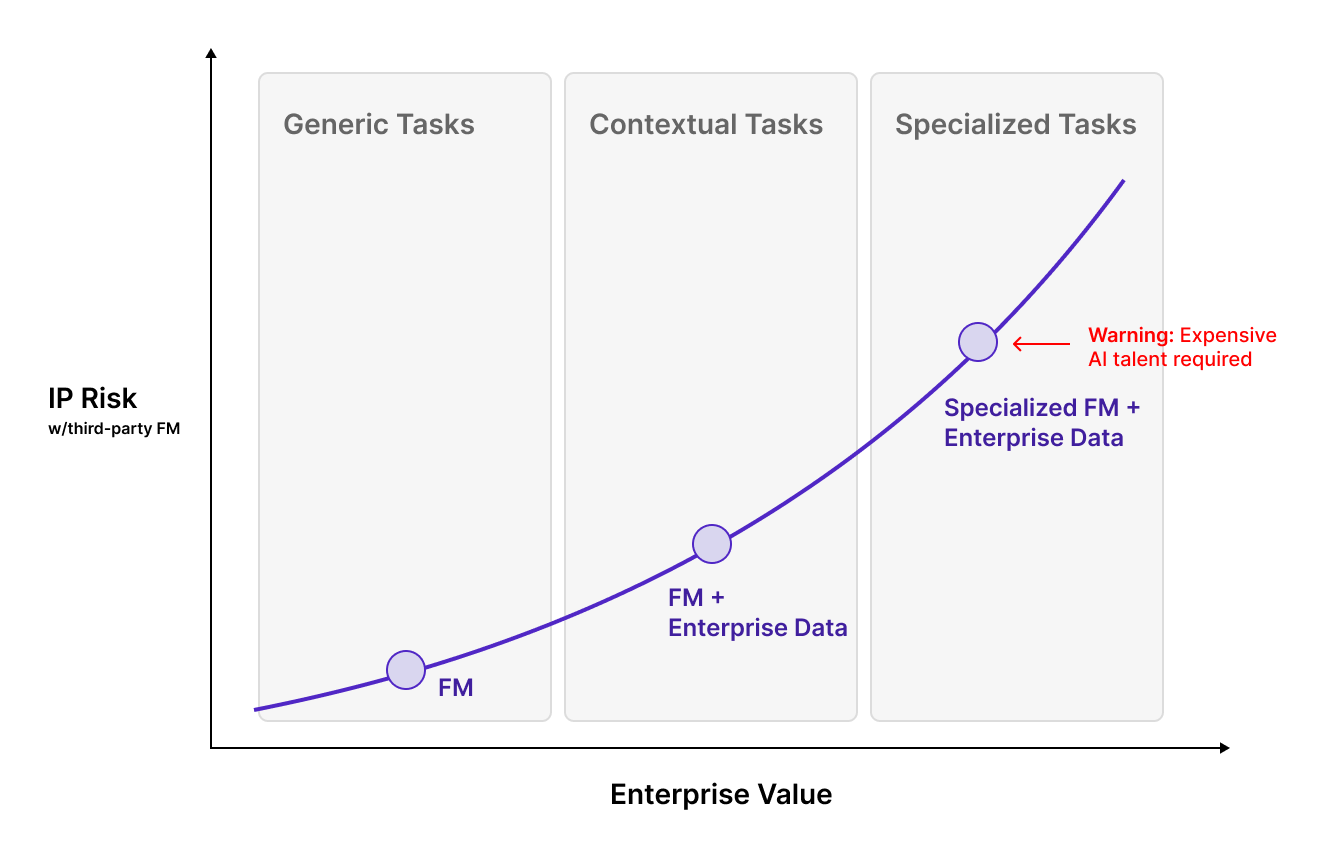
In the rapidly-evolving landscape of generative AI, third-party FMs are the de facto option today. These models offer a host of advantages, including a seamless setup process, lightning-fast prototyping capabilities, and access to cutting-edge models like GPT-4, crafted by industry giants like OpenAI. What’s more, these third-party FMs enable organizations to sidestep the intricate complexities of deploying and maintaining their own models, resulting in significant time and cost savings. As a result, they excel in handling generic tasks with non-sensitive data and swiftly constructing prototypes.To truly appreciate the potential of third-party FMs, let’s consider an example. Imagine you’re developing an application that assigns sentiment scores or summarizes movie reviews. In this case, all the data and knowledge you need to perform this task is readily available in the public domain. It’s the perfect scenario for a third-party FM to shine, allowing you to prototype your project rapidly. In this context, a third-party FM, trained on public data and queried for generic knowledge, is more than sufficient to get the job done efficiently.
Third-Party FM Concerns
However, the landscape changes when it comes to deploying FMs for specialized enterprise tasks. Consider a scenario where you ask a third-party FM, “Show me all my active users“. Here’s the catch: the FM has no knowledge of your specific user base or how “active” is defined within your enterprise. Achieving reliable results in such cases demands more than just a third-party FM; it necessitates the integration of contextual enterprise knowledge. But with this integration comes a host of other considerations, which we’ll explore in greater detail in the following section.
Context Begets IP Concerns
In the task of “Show me all my active users“, adding enterprise context to the FM is essential. We’ll explore two popular strategies to do this and their associated IP concerns when using a third-party FM.
In-Context Learning (RAG): Improving FM performance for specialized tasks often requires including context-specific data directly in the prompt or instruction to the model. Retrieval Augmented Generation (RAG), a widely adopted technique, does this by searching for and incorporating relevant context into the prompt. In our example, this would involve adding relevant user data directly into our prompt of “Show me active users“. However, this approach raises legitimate concerns about sharing sensitive enterprise data. While some vendors offer compliance assurances to address IP concerns, a fundamental question persists: Is user data alone sufficient, and how does the model grasp your unique definition of “active”?
Further Training a FM (Continual Pretraining or Fine-Tuning): To address the challenge of classifying users as “active,” one approach is to further train the FM via continual pretraining or task specific fine-tuning. Both processes here involve adding enterprise-specific knowledge, including internal business insights, directly into the FM. The end result is a significant performance boost on your organization’s tasks. However, doing this right requires an investment in expensive AI expertise. Even further, greater IP risks are incurred here when using a third-party FM as sensitive business information now resides in the model’s weights, which you do not own. Nevertheless, further training to an already pretrained FM remains a popular method to tailor FMs to your organization.
Based on our experience, both in-context learning and further training to a FM are needed in specialized fields like data analytics. However, as previously mentioned, they lead to heightened IP concerns with a third-party model, which can lead directly to vendor lock-in. This dilemma forces us to confront a critical question: should organizations surrender control of their FM to external entities? It’s akin to relinquishing proprietary data and insights, a decision that could have profound consequences and potentially compromise your ability to shape your AI-driven future.
Private FMs: Pros and Cons
The choice between utilizing a private FM or opting for a third-party model also presents a unique set of advantages and hurdles, making the decision a nuanced one for organizations looking to harness the power of foundation models.
Let’s dive deeper into the benefits of adopting a private FM. First and foremost, it enables you to harness the rapidly advancing community of open-source models, ensuring that your AI system remains up-to-date with the latest breakthroughs in the field. However, the most significant advantage lies in the resolution of lingering IP concerns. With a private FM, your organization gains complete ownership of its AI future, a critical factor when customizing the model for specialized enterprise tasks. This strategic move positions your company for sustained success, transitioning from the realm of mere prototypes to robust, production-ready solutions that endure the test of time.
However, navigating the path to establish a private FM is not without its challenges. It remains a complex, time-intensive, and financially demanding endeavor, often requiring rare and costly AI expertise. The development process may also be more time-consuming compared to the rapid prototyping possible with third-party FMs.
Overall, choosing between a private FM and a third-party alternative hinges on your organization’s unique needs and circumstances. While third-party FMs offer convenience, they also come with the potential risks of vendor lock-in and IP concerns, particularly when enterprise-specific context is essential. On the flip side, private FMs grant you control and ownership over your AI initiatives but demand a level of machine learning expertise that not all organizations possess. Weighing these factors carefully is essential to chart a course that aligns with your AI journey and sets you on the path to success.
| Third Party Model | Private Model | Numbers Station | |
|---|---|---|---|
| Fast Prototyping | ✔︎ | ✘ | ✔︎ |
| Affordable AI Talent | ✔︎ | ✘ | ✔︎ |
| Secure IP | ✘ | ✔︎ | ✔︎ |
| AI Independence | ✘ | ✔︎ | ✔︎ |
Table 1: The pros and cons of using a third-party FM, private FM, and Numbers Station. Numbers Station enables enterprises to leverage the best of each world while maintaining control of their AI future.
The Numbers Station Solution: Empowering Your AI Future
In specialized domains like data analytics, the choice between private and third-party FMs is a crucial one. It’s a decision that can significantly impact your control over data, safeguard your reputation, and determine the trajectory of your AI endeavors. At Numbers Station, we firmly advocate for the adoption of private FMs as the optimal solution for organizations seeking to maintain sovereignty over their AI initiatives.
Our unique approach at Numbers Station empowers organizations to harness the advantages of private FMs without encountering the associated drawbacks. Based on experiences collaborating with both large and small enterprises, we specialize in infusing essential, up-to-date enterprise knowledge directly into secure and private FMs. We understand that in today’s landscape, sacrificing privacy or ownership of crucial data is simply not an option for forward-thinking enterprises. That’s why we offer tailor-made solutions to our enterprise clients, eliminating the need for a dedicated AI team while preserving complete ownership and control of the model.
At Numbers Station, our team, led by AI PhDs from renowned institutions like Stanford and the University of Washington, is dedicated to enabling your organization’s AI future. We deliver customized, production-ready FMs that are finely tuned to meet the unique needs of your data organization. Our impressive track record includes numerous successes with enterprise clients, and we’re committed to sharing our learnings and innovations through top-tier open-source SQL models.
Choosing Numbers Station means choosing control over your AI future. It’s a decision that ensures you retain control over your sensitive business information, maintain your reputation, and steer your AI initiatives towards long-lasting success. With Numbers Station, the power to shape your AI future is firmly in your hands.