
We’ve seen incredible prototypes and demos of text-to-SQL solutions that show the dream of self-service analytics where business users, who have no knowledge of SQL or the underlying data, can ask questions to gain insights over their data. In this post, we’re going to explain why text-to-SQL is only an 80% solution and realizing self-service analytics requires moving away from the classical text-to-SQL paradigm.
Self-Service Analytics Dream
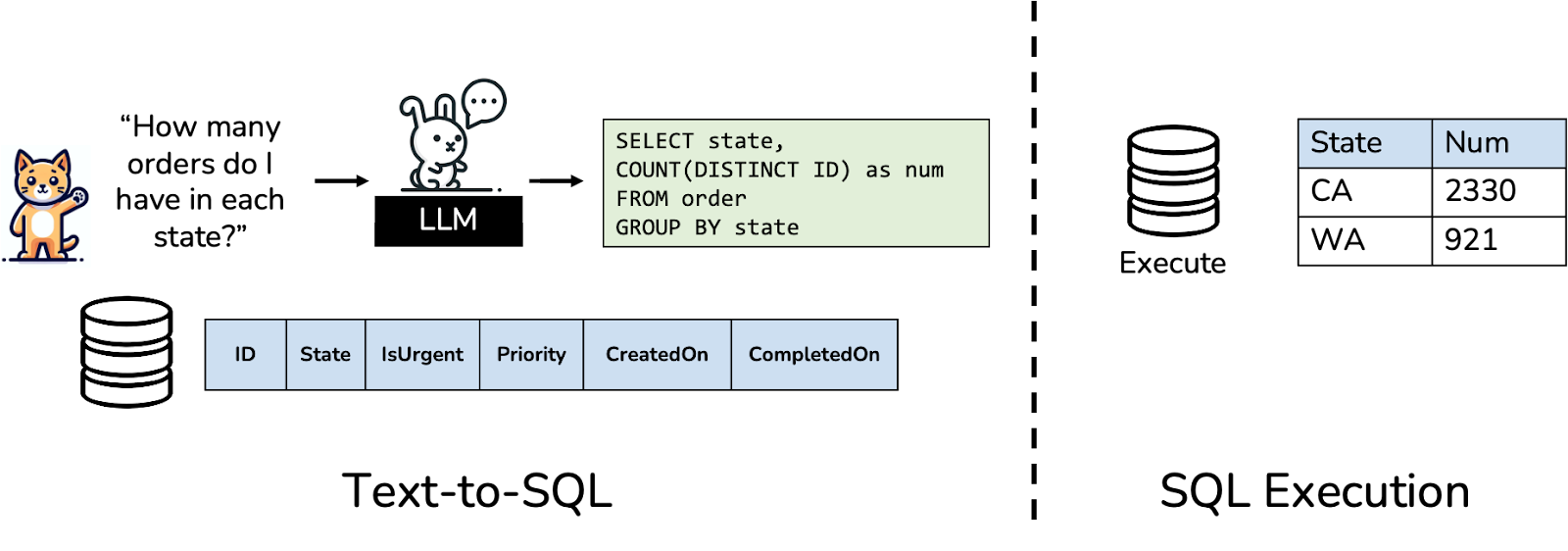
Since the 1980s, a natural language interface to your data has been a dream that promises democratization of data insights. Users with no understanding of SQL or the underlying data schema can ask questions over their data. Some of the earliest demos with Large Language Models (LLMs) showed how LLMs could be the breakthrough for text-to-SQL applications. Simply showing the database schema to the model along with the question (and some prompting tricks) results in a state of quality on academic text-to-SQL benchmarks with GPT-4. Products and open source efforts followed along, introducing easy to use pipelines and demos showcasing text-to-SQL use cases. The excitement made it seem like the dream of text-to-SQL was close to being realized.
Rubber Meets the Road – Direct Text-to-SQL Doesn’t Work
At Numbers Station, we deploy generative AI to help achieve self-service analytics and data processing across the enterprise data stack. We thought, as everyone, that LLMs could break open the text-to-SQL space. We built text-to-SQL solutions for some of the largest data teams in the world and soon realized that the text-to-SQL paradigm is fundamentally flawed for business users for three reasons.
1.) Business Lingo is not Model Lingo. Enterprise business analysts have no knowledge of the schema and use idiosyncratic business terminology to talk about their data. For example, suppose a warehouse of product orders has a field “Priority” with values “Urgent”, “High”, “Medium”, “Low”. A user can ask “How many P0 orders do I have?”. It’s ambiguous to the model what “P0 orders” means with respect to this schema and it will struggle to answer the user’s question faithfully.
2.) Business Users Don’t Know SQL. LLMs, even with the most advanced models and prompting tricks (i.e. in-context examples, RAG, asking the model to fix errors, etc), can still fail on advanced SQL queries. Enterprise data can have hundreds of tables and thousands of columns, causing models to struggle to output correct joins and nesting. The only viable way to correct the SQL is with a human-in-the-loop to correct the errors (a la GitHub CoPilot interface). Business users, however, do not know SQL and have no ability to correct errors. When models fail, it results in an uncorrectable error for the user.
3.) Privacy is a Dealbreaker. Enterprises are hesitant, if not unable, to use third party models due to sensitive data. Most of the state-of-the-art methods use third party models such as OpenAI to guarantee the highest SQL quality, making these solutions untenable for enterprises with privacy concerns. Further, while training a custom model is an option, it often requires hundreds of thousands of SQL queries enterprises rarely have on hand.
“Text-to-SQL” That Is Not Text-to-SQL

With these lessons learned, we started over and rebuilt a self-service analytics “text-to-SQL” tool from scratch that did not follow the traditional SQL model or data paradigm. Three of our core technical innovations are as follows.
1.) Curated a Knowledge Layer. Instead of just relying on the schema and metadata from the data, we introduce a knowledge layer as a layer between the data and the user questions. The knowledge layer codifies the business knowledge and terminologies and how business phrases map to the data. For example, a piece of information in the knowledge layer would be that “P0 Orders” are those where the column “Priority” is either “High” or “Urgent”. Including these definitions to the model allows for it to translate between user questions and data schema.
2.) Output To Semantics: Leaning into the knowledge layer even more, instead of asking the LLM to output SQL, we have the model output the exact semantic pieces of information it needs to answer the query. For example, given the question from above of “How many P0 orders do I have”, the model will output that it needs the metrics of “P0 Orders” and “Number of Orders” (which are defined in the knowledge layer) to answer the question. This intermediate query representation can then be automatically compiled to SQL, alleviating the need for the model to be a SQL syntax master. Further, outputting to the knowledge layer allows for the business users to give feedback to the model and overcome model mistakes.
3.) Llama-tize the Components: Now that we have broken our pipeline into concrete steps of generating semantic knowledge, incorporating it into the model, and generating semantics as the output, we can turn on individual components with private, custom models the enterprises can own. As demonstrated in our collaboration training a DuckDB text-to-SQL model, we address the data curation issue by relying on open source LLMs to generate training data for customization.
The Proof is in the Numbers (Pudding)
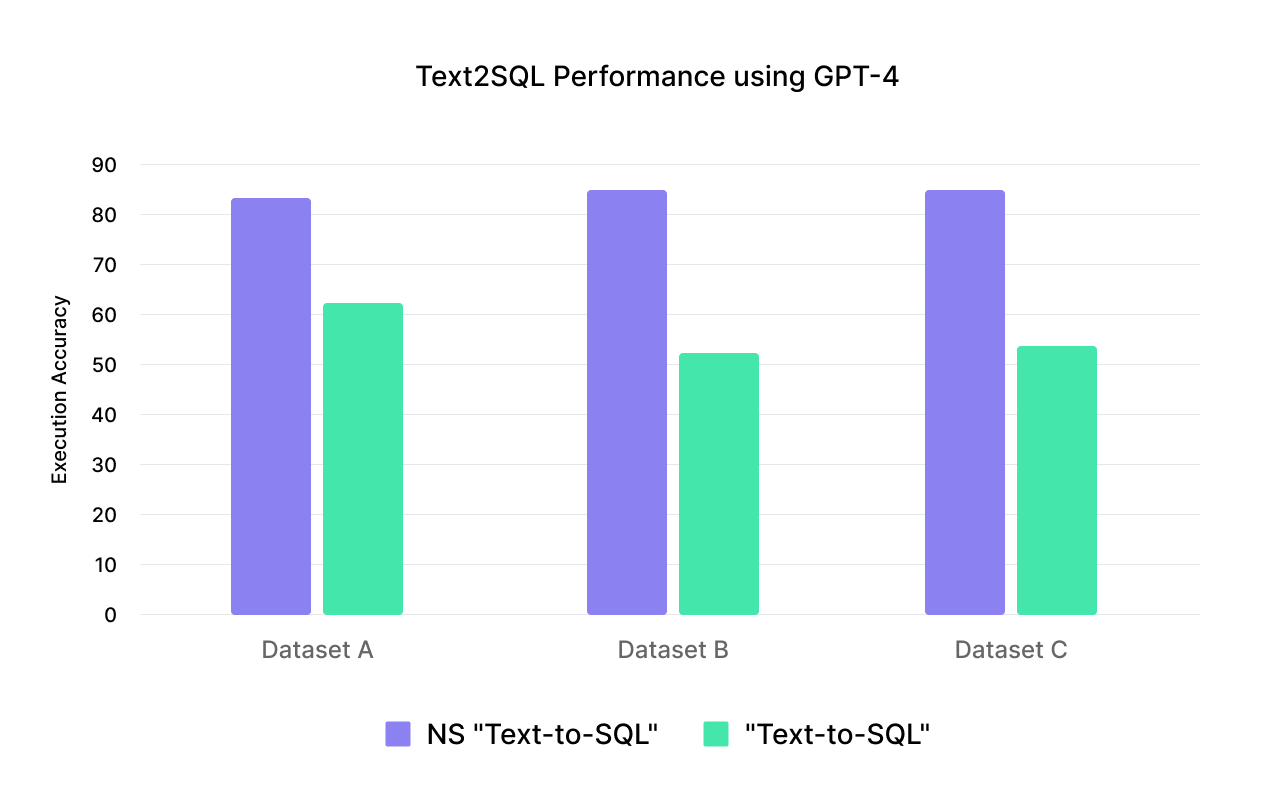
To showcase how the Numbers Station “text-to-SQL” pipeline outperforms more traditional text-to-SQL pipelines, we evaluate using GPT-4 on three proprietary datasets. We measure execution accuracy on the output queries and examine if the resulting table matches the gold table.
We see that across the board, the Numbers Station “text-to-SQL” outperformed traditional methods by 10 points or more of quality. Due to the knowledge graph, the model is better able to select the correct attributes given the user question. Further, the model never misses join patterns as the joins are determined at compile time rather than by the model.
Beyond “Text-to-SQL”
By a simple paradigm shift, we showed how to take a concrete step closer to delivering on a self-service analytics platform. While there are still open problems in how to handle user customization and answer high-level goal oriented questions, we could not be more excited by the future of text-to-not-SQL solutions. If you are curious to learn more, check out our video session discussing this topic with Stanford MLSys, reach out at info@numbersstation.ai and take a look at our other posts here.