
Numbers Station Labs is excited to release Meadow, the first agentic framework built for data workflows. Mutli-AI-agent architectures are proving to be the key to solving highly complex tasks with AI that one model alone cannot solve, and are paving the way for end-to-end task automation. At Numbers Station Labs, we strengthen data teams by using LLMs to increase productivity. We believe a multi-agent framework built specifically for data tasks can allow for end-to-end analytical workflow automation. None of the existing general-purpose agent frameworks are tailor-built for data analysts and as a result, we rolled out Meadow—the first multi-agentic framework for data tasks. Early results show that Meadow, without any expensive labeled examples, is within 3.6 points of state-of-the-art on the Spider text-to-SQL benchmark and realizes lifts of up to 20 points over simple, zero-shot text-to-SQL prompts. Meadow is also capable of detecting data errors and uncovering incorrect Spider benchmark queries that did not take into account extra white spaces in the data. Meadow is fully open source, and we’re excited to see how it evolves to continue to help researchers apply LLMs to their data tasks.
.
Why Meadow
AI agents are Large Language Models (LLMs) programmed to perform a specific task or role and can often take action in their environment via calling APIs. From single tool agents to multi-agent collaborations, researchers find that by specializing the role of an agent, a network of multiple agents can break down complex tasks and perform better than single agents can. As a result, we’ve seen a proliferation of inspiring examples of general-purpose agentic frameworks such as AutoGen, TaskWeaver, MetaGPT, and LangChain. These frameworks show how to automate end-to-end workflows such as code generation and question answering. It’s only natural to ask: what can agentic frameworks do for data workflows?
Data workflows are multi-step processes where an analyst first transforms, generates, and analyzes structured data to gain insights and take action. For example, an analyst may want to run a trend analysis on sales data. The workflow to achieve this includes multiple, diverse steps: data integration, schema cleaning, text-to-SQL generation, and report generation for business stakeholders. These laborious workflows build the framework of enterprise-level decision-making and require business knowledge about the task and data to accomplish.
Prior work has gone into applying LLMs to individual components of the workflow, e.g. LLMs for record matching and data cleaning. However, without fully automating the complete workflow, enterprises suffer from decision-making bottlenecks as analysts are still required to be deeply involved in the workflow completion and in actioning the results. LLM agents hold the promise to automate complete data workflows with minimal user feedback and allow enterprises to derive business insights more efficiently and cheaply. More importantly, LLM agents can take action on the results by generating reports, filing tickets, or sending results and actually help enterprises get work done. With Meadow, we’ve built the simplest agentic framework for completing data workflows.
.
.
The Meadow Approach

Meadow began as an attempt to implement simple data workflows in existing general-purpose agentic frameworks. While we liked the engineering simplicity and modularity of agents communicating with each other via message passing, we quickly realized existing frameworks lacked the paradigms needed to specialize in data tasks. Specifically,
- No shared data layer. No framework had an agentic data layer as a first-class primitive to all agents. Data cannot be passed via context alone as the data can be massive. While some frameworks support a database for SQL agents, there was no end-to-end shared data layer abstraction easily shared between all agents.
- No data-aware nested task breakdowns. Data workflows begin with high-level goals broken down into multiple hierarchies of tasks that depend on the data. For example, if the analyst wants to understand their sales and the schema is successfully normalized and easy to understand, an analyst can directly start issuing SQL aggregates to understand trends. If the schema is confusing, they may need to explore the data via a sequence of subtasks and add constraints to understand how to join before moving on to SQL. While existing frameworks have planners, they lack the ability to hierarchically plan between multiple groups of agents in a data-aware fashion.
- No iterative data debugging. Even analysts run into incorrect queries or results due to the complexity of SQL and changing data schemas/constraints. Knowledge of the data is required to fix many of the errors. For example, understanding how certain columns join can avoid incorrect SQL joins that return empty tables. While some frameworks had code execution and used model error correction to fix mistakes, they lacked the customization needed to support data-aware debugging.
Inspired by AutoGen and other frameworks, Numbers Station Labs have built Meadow from scratch and made three core contributions to address the challenges above.
- All agents are data agents. All agents have access to a shared data layer that allows for querying and modifying the data/schema. This allows for communicating data changes seamlessly between models. Further, models enhance the data layer with LLM-friendly names and descriptions of queries and views to improve semantic understanding of business data.
- Hierarchical data plans. Data tasks require high and low-level planning across the data stack. Meadow supports “Planner Agents” that see the data and generate plans that are coordinated among their available agents. This allows for a natural way of branching and chaining tasks into simpler substeps.
- Every task has an associated checker and debugger. The output of many data tasks is itself a structured output (a SQL query or view definition). All of these outputs are verifiable and iterated on by analysts in the case of bugs. We bake this notion into Meadow by providing “Executor Agents” that determine if an output is correct and if not, can query the data interactively or use model error correction to fix the mistake.
Further, to keep debugging easier and allow for user feedback, we use a simple paradigm where two agents chat at any time moderated through a “Router Agent”.
.
.
Meadow in Action
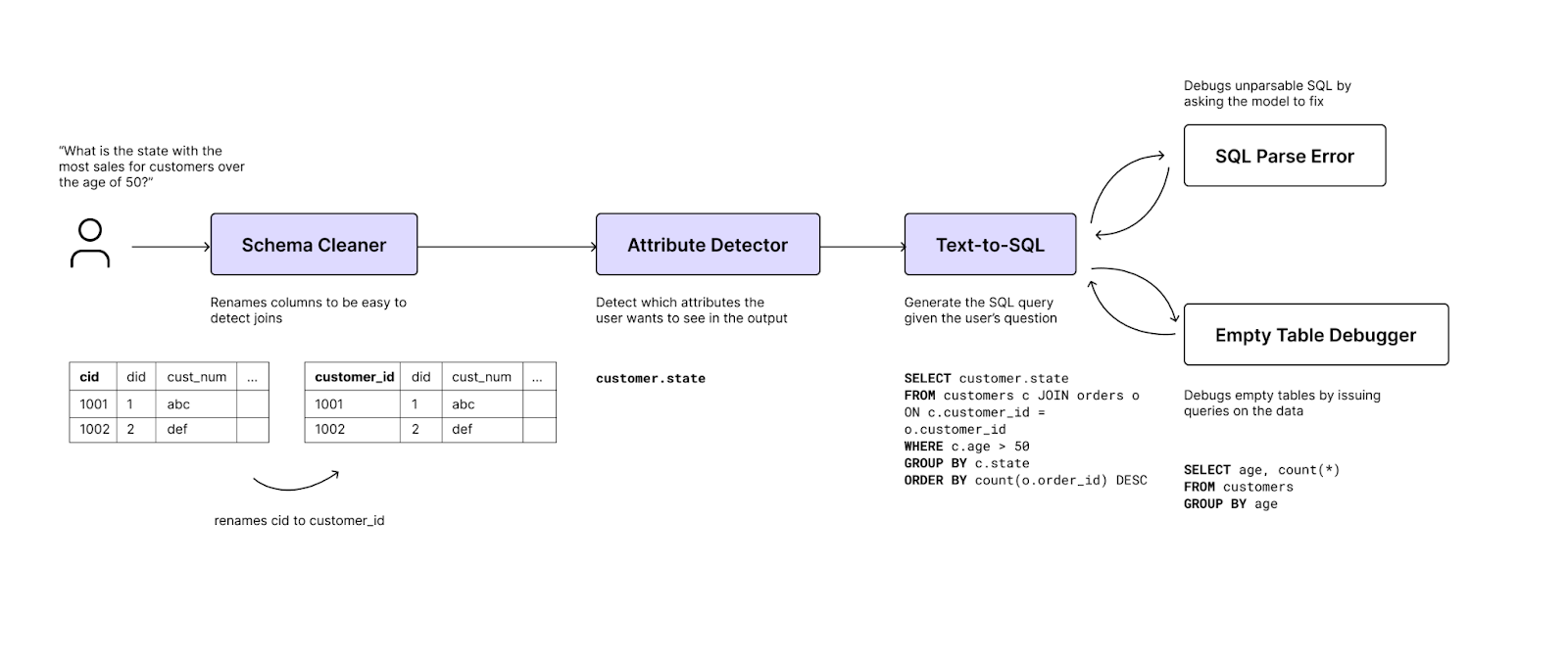
We want to put Meadow to the test. We decided to go back to the classic text-to-SQL workflow of transforming a user’s natural language instruction into a SQL query. Unlike traditional text-to-SQL approaches that focus on making the single best text-to-SQL agent through techniques like chain-of-thought and few-shot prompting, we keep our text-to-SQL agent very simple—there are no expensive demonstrations and a simple prompt that just provides the schema and question. As shown in Figure 2, we treat text-to-SQL as a workflow problem and add upstream agents that perform other data tasks to improve the downstream performance of text-to-SQL. Specifically, we add an upstream “Schema Cleaner Agent” that renames data columns to better represent the joins, and we add an “Attribute Selector Agent” that narrows down the attributes required for the query. Lastly, we use two executor agents. One that simply detects SQL parsing errors and asks the model to correct them (called “SQL Validator”). Another is an empty table debugger that processes the output of the text-to-SQL agent and debugs against the database if the resultant SQL outputs an empty table.
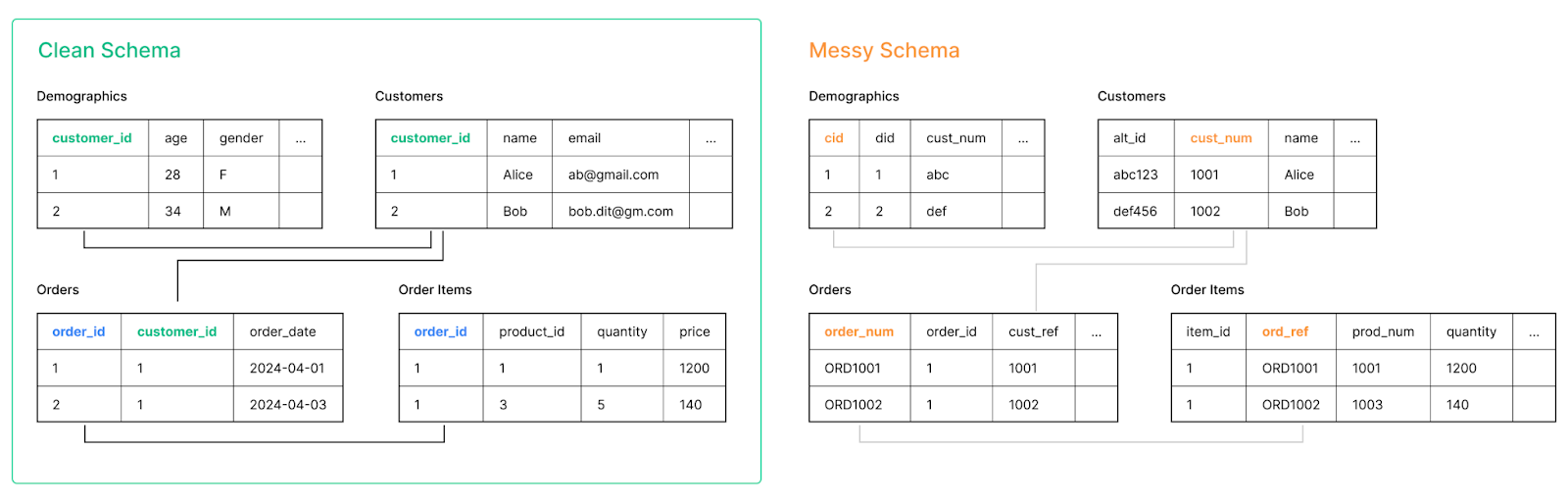
We evaluate on two benchmarks, Spider V1 and a Numbers Station 50-question benchmark inspired by real Numbers Station enterprise workloads with heavily nested SQL queries over two sales databases, as shown in Figure 3. One is a clean schema with standardized columns and join keys. The other is modified to have misleading join keys that do not match by name. For Spider, we use execution accuracy from here and for our benchmark, we use execution accuracy from here1. As explained in more detail below, we modify the gold data for the flight_2 database for Spider to accurately take into account the fact that the flight_2 database has extra spaces added to values in columns such as city and airport.
- We found the Spider execution accuracy gave incorrect results for complex, nested gold queries so rewrote the execution accuracy for our benchmark} ↩︎
.
Spider V1 (Modified Gold Set)
| Single Text-to-SQL Prompt | + SQL Validator | + Attribute Detector | + Schema Cleaner | + Empty Table Debugger | |
| Exec Acc* | 73.5 | 73.5 | 78.9 | 79.9 | 80.9 |
*To address the fact that the flight_2 database has white spaces at the end of airport codes and cities, we modify the gold queries over flight_2 to have the SQL TRIM command on WHERE clauses and equality join conditions.
Numbers Station Benchmark
| Single Text-to-SQL Prompt | + SQL Validator | + Attribute Detector | + Schema Cleaner | + Empty Table Debugger | |
| Exec Acc | 53.0 | 53.0 | 55.2 | 72.5 | 73.1 |
Table 1 and Table 2 ablate Meadow with different configurations of agents added to the pipeline. We see consistent lifts of adding more agents to the pipeline across both benchmarks. For Spider, the attribute detector is the most useful agent as many models tend to output too many attributes than strictly asked in the question. For example, in the question “Which model has the most version(make) of cars?”, the gold answer just gives the model while many LLMs give the model and number of cars. For the Numbers Station benchmark, the schema cleaner improves performance the most as it helps rename the misleading joins to be easier to detect for the model.
As mentioned above, the Spider results in Table 1 are over a modified eval set. After implementing the empty table debugger, we noticed a drop in performance on the accuracy of questions over the flight_2 database which has information on airlines, flights, and airports. Upon investigation, we noticed columns such as airport city and airport code have extra white spaces added, and the Spider gold query does not account for this. For example, the gold question of “Give the airport code and airport name corresponding to the city Anthony.” has the gold query with a filter of WHERE city = ‘Anthony’. This returns an empty result because the real filter should be WHERE city = ‘Anthony ’ (space at the end). Our empty table debugger uncovered and corrected this mistake. As a result, we show performance numbers with the corrected flight_2 filters.
Spider V1
| Gao (Zero Zhot) | Wang (Zero Shot) | Meadow (Zero Shot) | Gao (Few Shot) | Wang (Few Shot) | |
| Exec Acc | 74.4 | 74.22 | 83.2 | 84.4 | 86.75 |
To compare against prior works, in Table 3, we show the standard Spider execution accuracy on the dev set without modifying the gold queries and compare against state-of-the-art approaches from Gao et. al. and Wang et. al.. Wang et. al. is the closest to Meadow and uses multiple agents. However, their pipeline is fixed and none of their agents can take actions (e.g. execute queries to debug a result). We see Meadow is only 3.6 points away from the state-of-the-art without using expensive hand-labeled examples. Other methods rely heavily on multiple labeled text-to-SQL pairs, and Meadow surpasses their zero-shot approaches by 8.8 points.
.
.
Final Remarks
We couldn’t be more excited about the future of Meadow. These early results on text-to-SQL highlight how bringing agents to the entire data analytics workflow can improve performance and bring about full workflow automation for data analysts. Please take a look at the Meadow repo and give us a star. If you have any questions, please reach out to laurel.orr@numbersstation.ai or info@numbersstation.ai.